Structured writing involves separating content from formatting, as we move content out of the media domain. But to publish content, we have to get it back into the media domain by reuniting content and formatting.

Structured writing involves separating content from formatting, as we move content out of the media domain. But to publish content, we have to get it back into the media domain by reuniting content and formatting.

Single sourcing was one of the earliest motivations for structured writing. However, the term single sourcing gets used to mean different things, all of which involve a single source in one way or another, but which use different approaches and achieve different ends. To make life easier, I distinguish three main meanings of single sourcing as follows:
In this article we will look at single sourcing as defined above.
The basic single sourcing algorithm is straightforward and we have covered most of it already in the discussion of basic content processing.
Basic single sourcing involves taking a piece of content in the document domain and processing its document domain structures into different media domain structures for each of the target media.
Suppose we have a recipe recorded in the document domain, using the syntax that I have been using throughout this series. (The block of text set of by blank lines is implicitly a paragraph — a structure named p.)
page:title: Hard Boiled EggsA hard boiled egg is simple and nutritious. Prep time, 15 minutes. Serves 6.section: Ingredientsul:li: 12 eggsli: 2qt watersection: Preparationol:li: Place eggs in pan and cover with water.li: Bring water to a boil.li: Remove from heat and cover for 12 minutes.li: Place eggs in cold water to stop cooking.li: Peel and serve.
We can output this recipe to two different media by applying two different formatting algorithms. First we output to the Web by creating HTML. (See the article on processing structured writing for an introduction to the pseudocode used for these examples.)
match pagecreate htmlstylesheet www.example.com/style.csscontinuematch titlecreate h1continuematch pcopycontinuematch sectioncontinuematch section/titlecreate h2continuematch ulcopycontinuematch olcopycontinuematch licopycontinue
In the code above, paragraph and list structures have the same names in the source format as they do in the output format (HTML) so we just copy the structures rather than recreating them. This is a common pattern in structured writing algorithms. (Though complications can arise with something called namespaces, which we will discuss later.)
The above algorithm should transform our source into HTML that looks like the following:
<html><head><link rel="stylesheet" type="text/css" href="//www.apache.org/css/code.css"></head><h1>Hard Boiled Eggs</h1><p>A hard boiled egg is simple and nutritious. Prep time, 15 minutes. Serves 6.</p><h2>Ingredients</h2><ul><li>12 eggs</li><li>2qt water</li></ul><h2>Preparation</h2><ol><li>Place eggs in pan and cover with water.</li><li>Bring water to a boil.</li><li>Remove from heat and cover for 12 minutes.</li><li>Place eggs in cold water to stop cooking.</li><li>Peel and serve.</li></ol></html>
Outputting to paper (or to PDF, which is a kind of virtual paper) is more complex. On the Web, you output to a screen which is of flexible width and infinite length. The browser generally takes care of wrapping lines of text to the screen size (unless formatting commands tell it to do otherwise) and there is no issue with breaking text from one page to another. For paper, though, you have to format for a fixed size page—you must fit the content into a set of fixed size pages.
This leads to a number of formatting problem, such as where to break each line of text, how to avoid a heading appearing at the bottom of a page or the last line of a paragraph appearing as the first line of a page. It also creates issues with references. For instance, a reference to content on a particular page cannot be known until the algorithm paginates the content.
Consequently, you don’t write a formatting algorithm for paper directly, the way you would write an algorithm to output HTML. Rather, you use an intermediate typesetting system which already knows how to handle things like inserting page number references and determining line and page breaks. Rather than handling these things yourself, you tell the typesetting system how you would like it to handle them and then let it do its job.
One such typesetting system is XSL-FO (Extensible Stylesheet Language – Formatting Objects). XSL-FO is a typesetting language written in XML. To format you content using XSL-FO, you transform your source content into XSL-FO markup, just the way you transform it into HTML for the Web. Then you run the XSL-FO markup through an XSL-FO processor to produce your final output, such as PDF. (I call this the encoding algorithm.)
Here is a small example of XSL-FO markup:
<fo:block space-after="4pt"><fo:wrapper font-size="14pt" font-weight="bold">Hard Boiled Eggs</fo:wrapper></fo:block>
As you can see, the XSL-FO code contains a lot of specific media domain instructions for spacing and font choices. The division between HTML for basic structures and CSS for specific formatting does not exist here. Also note that as a pure media-domain language, XSL-FO does not have document domain structures like paragraphs and titles. From its point of view a document consists simply of a set of blocks with specific formatting properties attached to them.
Because of all this detail, I am going to show the literal XSL-FO markup in the pseudocode of the algorithm, and I am not going to show the algorithm for the entire recipe. (The point is not for you to learn XSL-FO here, but to understand how the single-sourcing algorithm works.)
match titleoutput '<fo:block space-after="4pt">'output '<fo:wrapper font-size="14pt" font-weight="bold">'continueoutput '</fo:wrapper>'output '</fo:block>'
Other typesetting systems you can use for print output include TeX and later versions of CSS.
Basic single sourcing outputs the same document to different media. But each media is different, and what works well in one media does not always work as well in another. For example, online media generally support hypertext links, while paper does not. Let’s suppose that we have a piece of content that includes a link.
{The Duke}(link "http://JohnWayne.com") plays an ex-Union colonel.
In the markup language I am using here (and will eventually explain) the piece of markup represented by “http://JohnWayne.com” specifies the address to link to. In the algorithm examples below, this markup is referred to as the specifically attribute using the notation @specifically.
In HTML we want this output as a link using the HTML a element, so we write the algorithm like this:
match pcopycontinuematch linkcreate aattribute href = @specificallycontinue
The result of this algorithm is:
<p><a href="http://JohnWayne.com">The Duke</a>plays an ex-Union colonel.</p>
But suppose we want to output this same content to paper. If we output it to PDF, we could still create a link just like we do in HTML, but if that PDF is printed, all that will be left of the link will be a slight color change in the text and maybe an underline. It will not be possible for the reader to follow the link or see where it leads.
Paper can’t have active links but it can print the value of URLs so that reader can type them into a browser if they want to. An algorithm could do this by printing the link inline or as a footnote. Here is the algorithm for doing it inline. (We’ll dispense with the complexity of XSL-FO syntax this time.)
match pcreate fo:blockcontinuematch linkcontinueoutput " (see: "output @specificallyoutput ") "
This will produce:
<fo:block>The Duke (see: http://JohnWayne.com) plays an ex-Union colonel</fo:block>
This works, but we should note that the effect is not exactly the same in each media. Online, the link to JohnWayne.com serves to disambiguate the phrase The Duke for those readers who do not recognize it. A simple click on the link will explain who the Duke is. But in the paper example, such disambiguation exists only incidentally, because the words JohnWayne happen to appear in the URL. This is not how we would disambiguate The Duke if we were writing for paper. We would be more likely to do something like this:
The Duke (John Wayne) plays an ex-Union colonel.
This provides the reader with less information, in the sense that it does not give them access to all the information on JohnWayne.com, but it does the disambiguation better and in a more paper-like way. The loss of the reference to JohnWayne.com is probably not an issue here. Following that link by typing it into a browser is a lot more work than simply clicking on it on a Web page. If someone reading on paper wants more information on John Wayne they are far more likely to type John Wayne into Google than type JohnWayne.com into the address bar of their browser.
With the content written as it is, though, there is no easy way to produce this preferred form for paper. While the content is in the document domain, the choice to specify a link gives it a strong bias towards the Web and online media rather than paper. A document domain approach that favored paper would similarly lead to a poorer online presentation that omitted the link.
What we need to address the problem is a differential approach to single sourcing, one that allows us to differ not only the formatting but the presentation of the content for different media.
One way to accomplish this differential single sourcing is to record the content in the subject domain, thus removing the prejudice of the document domain representation for one class of media or another. Here is how this might look:
{The Duke}(actor "John Wayne") plays an ex-Union colonel.
In this example, the phrase The Duke is annotated with a subject domain annotation that clarifies exactly what the text refers to. That annotation says that the Duke is the name of an actor, specifically John Wayne.
Our document domain examples attempt to clarify the Duke for readers, but do so in media-dependent ways. This subject domain example clarifies the meaning of The Duke in a formal way that makes the clarification available to algorithms. Because the algorithm itself has access to the clarification, it can produce either kind of clarifying content for the reader by producing either document domain representation.
For paper:
match actorcontinueoutput " ("output @specificallyoutput ") "
For the Web:
match actorcreate link$href = get link for actor named @specificallyattribute href = $hrefcontinue
This supposes the existence of a system that can respond to the get link instruction and look up pages to link to based on the type and a name of a subject. We will look at how a system like that works in a future article on linking.
Differences in presentation between media can be broader than this. Paper documents sometimes use complex tables and elaborate page layouts that often don’t translate well to online media. Effective table layout depends on knowing the width of the page you have available, and online you don’t now that. A table that looks great on paper may be unreadable on a mobile device, for instance.
And this is more than a layout issue. Sometimes the things that paper does in a static way should be done in a dynamic way in online media. For example, airline or train schedules have traditionally been printed as timetables on paper, but you will virtually never see them presented that way online. Rather, there will be an interactive travel planner online that lets you choose your starting point, destination, and desired travel times and then presents you with the best schedule, including when and where to make connections.
Single sourcing your timetable to both print and PDF outputs will not produce the kind of online presentation of your schedule that people expect, and that can have a direct impact on your business.
To single source schedule information to paper and online successfully, you can’t maintain that content in a document domain table structure. You need to maintain it in a timetable database structure (which is subject domain, but really looks like a database—not a document at all).
An algorithm, which I call the synthesis algorithm, can then read the database to generate a document domain table for print publication. For the Web, however, you will create a web application that queries the database dynamically to calculate routes and schedules for individual travelers.
Differences in linking between media can go much deeper than how the links are presented. Links are not simply a piece of formatting like bold or italics. Links connect pieces of content together. On paper, documents are designed linearly, with one section or chapter after another. But online you can organize information into a hypertext with links that allow the reader to navigate and read in many different sequences.
The difference between linear information design and hypertext information design is not a media domain distinction but a document domain distinction. But if you are thinking about single sourcing your content it is a difference you must consider. In other words, single sourcing is not just about one document domain source with many media domain outputs. It can also be about a single subject domain source with multiple document domain outputs expressing different information designs, and outputting to different media.

More radical forms of differential single sourcing start to look a lot like reusing the same content to build quite different documents (albeit on the same subject) and therefore start to use the techniques of content reuse, which we will deal with in the next article.
You can also do differential single sourcing by using conditional (management domain) structures in the document domain.
For instance, if you are writing a manual that you intend to single source to a help system, you might want to add context setting information to the start of a section when it appears in the help system. The manual may be designed to be read sequentially, meaning that the context of individual sections is established by what came before. But help systems are always accessed randomly, so the context of a particular help topic may not be clear if it was single sourced from a manual. To accommodate this, you could include a context setting paragraph that is conditionalized to appear only in help output:
section: Wrangling left-handed widgets~~~(?help-only)Left-handed widgets are used when wrangling counter-clockwise.To wrangle a left handed widget:1. Loosen the doohickey using a medium thingamabob.2. Spin three times around under a full moon.3. Touch the sky.
In the markup above, the ~~~ creates a fragment structure to which conditional tokens can be applied. Content indented under the fragment marker is part of the fragment.
To output a manual, we suppress the help-only content:
match fragment where conditions = help-onlyignore
To output help, we include it:
match fragment where conditions = help-onlycontinue
While there is a lot you can do in the way of differential single sourcing to successfully output documents that work well in multiple media, there are limits to how far this approach can take you.
In the end, linear and hypertext approach a fundamentally different ways of writing which invite fundamentally different ways of navigating and using information. Even moving content to the subject domain as much as possible will not entirely factor out these fundamental differences of approach.
When single sourcing content to both linear paper-like media and hypertext web-like media, you will generally have to choose a primary media to write for. Single sourcing that content to the other media will be on a best-effort basis. It may be good enough for a particular purpose, but it will never be quite as good as it could have been had you designed for that media.
Many of the tools used for single sourcing have a built in bias towards one media or another. Desktop-publishing tools like FrameMaker, for instance, were designed for linear media. Online collaborative tools like wikis were designed for hypertext media. It is usually a good idea to pick a tool that was designed for the media you choose as your primary.
In many cases, the choice of primary media is made implicitly based on the tools a group has traditionally been using. This usually means that the primary media is paper, and it often continues to be so even after the group had stopped producing paper and their readers are primarily using online formats.
Some organizations seem to feel that they should only switch to tools that are designed primarily for online content when they have entirely abandoned the production of paper and paper-like formats such as PDF. This certainly does not need to be the case. It is perfectly possible to switch to an online-primary tools and still produce linear media as a secondary output format.
Manual-oriented tools such as FrameMaker start with the manual format and then break it down into topics for the help system (usually by means of a third party tool). The results are often poorly structured help topics. For instance, it is common to see the introduction to a chapter transformed into a stand alone topic that conveys no useful help information at all.
Help authoring tools start with help topics and then build them up into manuals, which they may do either by stringing them together linearly, or mapping them into a hierarchy via a map or a table of contents. While help authoring tools should nominally optimize for help and then do the best they can for manuals, users of help authoring tools often focus on the manual format more than the help, so the use of a HAT does not guarantee that the help format gets design priority. The same is true of topic-oriented document domain systems like DITA. They are often still used to produce document-oriented manuals and help systems, with the topics being mostly used as building blocks.
Changing your information design practices from linear paper based designs to hypertext Every Page is Page One designs is non-trivial, but such designs better suit the way many people use and access content today. Don’t expect single sourcing to successfully turn document-oriented design into effective hypertext by themselves. To best serve modern readers it will usually be much more effective to adopt an Every Page is Page One approach to information design and use structured writing techniques to do a best-effort single sourcing to linear media for those of your readers who still need paper or paper-like formats.

When you deliberately create content for reuse, you need to place constraints on the content to be reused and the content that reuses it, and that puts you in the realm of structured writing.

All structured writing must eventually be published. Publishing structured content mean transforming it from the domain in which it was created (subject domain, document domain, or the abstract end of the media domain) to the most concrete end of the media domain spectrum: dots on paper or screen.
In almost all structured writing tools, this process is done in multiple steps. Using multiple steps makes it easier to write and maintain code and to reuse code for multiple purposes.
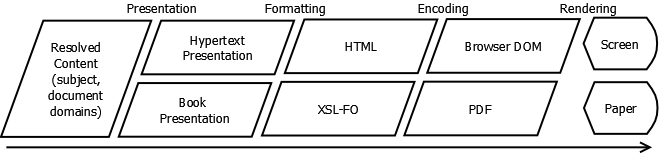
In this article, I describe the publishing process as consisting of four basic algorithms which I have mentioned in passing in earlier articles: the synthesis, presentation, formatting, and encoding algorithms. This is a model of the publishing process. All the processes in the model have to occur somewhere in every actual publishing process, but the organization of those processes may be subdivided or sequenced differently from this model. I formalized these four stages in the SPFE architecture (which I will discuss later), but I think they are a fair representation of what goes on in most publishing tool chains. To understand the requirements of each stage and the impact on the structured writing, we’ll look at the process from finished output backwards to creation and synthesis.
There is actually a fifth algorithm in the publishing chain, which we can call the rendering algorithm. The rendering algorithm is the one responsible for actually placing the right dots on the right surface, be that paper, screen, or a printing plate. But this is a low-level device-specific algorithm and no one in the structured writing business is likely to be involved in writing rendering algorithms. The closest we ever get is the next step up, the encoding algorithm. However an introduction to rendering is important to understanding the four publishing algorithms work together.
 The rendering algorithm requires some form of input to tell it where to place the dots. In writing, this usually comes in the form of something called a page description language. Like it sounds, this is a language for describing what goes where on a page, but in higher level terms than describing where each dot of ink or pixel of light is placed. A page description language deals in things like lines, circles, gradients, margins, and fonts.
The rendering algorithm requires some form of input to tell it where to place the dots. In writing, this usually comes in the form of something called a page description language. Like it sounds, this is a language for describing what goes where on a page, but in higher level terms than describing where each dot of ink or pixel of light is placed. A page description language deals in things like lines, circles, gradients, margins, and fonts.
One example of a page description language is PostScript. We looked at a small example of PostScript in the article on the media domain:
100 100 50 0 360 arc closepathstroke
Since most writers are not going to write directly in a page description language, the page descriptions for your publication are almost certainly going to be created by an algorithm. I call this the encoding algorithm.
While it is possible that someone responsible for a highly specialized publishing tool chain may end up writing a specialized encoding algorithm, most encoding algorithms are implemented by existing tools that translate formatting languages into page descriptions languages.
 There are several formatting languages that are used in content processing. They are often called typesetting languages as well. XSL-FO (XSL – Formatting Objects) is one of the more commonly used in structured writing projects. TeX is another.
There are several formatting languages that are used in content processing. They are often called typesetting languages as well. XSL-FO (XSL – Formatting Objects) is one of the more commonly used in structured writing projects. TeX is another.
Here is an example of XSL-FO that we looked at in the article on the single-sourcing algorithm:
<fo:block space-after="4pt"><fo:wrapper font-size="14pt" font-weight="bold">Hard Boiled Eggs</fo:wrapper></fo:block>
You process XSL-FO using an XSL-FO processor such as Apache FOP. Thus the XSL-FO processor runs the encoding algorithm, producing a page description language such as PostScript or PDF as an output.
Writers are not likely to write in XSL-FO directly, though it is not entirely impossible to do so. In fact some boilerplate content, such as front matter for a book, does sometimes get written and recorded directly in XSL-FO. (I did this myself on one project.) So, as you construct a publishing tool chain, you will need to select and integrate the appropriate encoding tools as part of your process.
The encoding algorithm takes a high level description of a page or a set of pages, their content and their formatting, and turns it into a page description language that lays out each page precisely. For publication on paper, or any other fixed-sized media, this involves a process called pagination: figuring out exactly what goes on each page, where each line breaks, and when lines should be bumped to the next page.
The pagination function figures out, for example, how to honor the keep-with-next formatting in an application like Word or FrameMaker. It must also figure out how to deal with complex figure such as tables: how to wrap text in each column, how to break a table across pages, and how to repeat the header rows when a table breaks to a new page. Finally, it has to figure out how to number each page and then fill in the right numbers for any references that include a particular page number.
This is all complex and exacting stuff and, depending on your requirements, you may have to pay some attention to make sure that you are using a formatting language that is capable of doing all this the way you want it done.
Also, you should think about just how automatic you want all of this to be. In a high-volume publication environment, you want it to be fully automatic, but this could require some compromises. For example, writers and editors sometimes make slight edits to the actual text of a document in order to make pagination work better. This is very easy to do when you are working in the media domain in an application like Word or FrameMaker. If you end up with the last two words of a chapter at the top of a page all by itself, for instance, it is usually possible to find a way to edit the final paragraph to reduce the word count just enough to pull the end of the chapter back to the preceding page. But this sort of thing is much harder when you are writing in the document domain or the subject domain, particularly if you are single sourcing content to more than one publication or reusing content in many places. An edit that fixes one pagination problem could cause another, and a major reason for writing in those domains it to take formatting concerns off the author’s plate.
For Web browsers and similar dynamic media viewers, such as E-Book readers or help systems, the whole pagination process takes place dynamically when the content is loaded into the view port, and it can be redone on the fly if the reader resizes their browser or rotates their tablet. This means the publisher has very little opportunity to tweak the pagination process. They can guide it by providing rules such as keep-together instructions through tools like cascading style sheets (CSS), but they obviously cannot hand tweak the text to make it fit better each time the view port is resized.
The formatting language for these kinds of media is typically HTML+CSS.
The formatting algorithm generates the formatting language that drives the encoding and pagination process. In other words, the formatting algorithm produces the media domain representation of the content from content in the document domain.
 In the case of HTML output, the formatting algorithm generates HTML (with connections to the relevant CSS, JavaScript, and other formatting resources). This is the end of the publishing process for the Web, since the browser performs the encoding and rendering algorithms internally.
In the case of HTML output, the formatting algorithm generates HTML (with connections to the relevant CSS, JavaScript, and other formatting resources). This is the end of the publishing process for the Web, since the browser performs the encoding and rendering algorithms internally.
In the case of paper output, the formatting algorithm generates a formatting language, such as TeX or XSL-FO, which is then fed to the encoding algorithm as implemented by a TeX or XSL-FO processor. In some cases, organizations use word processing or desktop publishing applications to tweak the formatting of the output by having the formatting algorithm generate the input format of those applications (typically RTF for Word and MIF for FrameMaker). This allows them to exercise manual control over pagination, but with an obvious loss in process efficiency. In particular, any tweaks made in these applications are not routed back to the source content, so they must be done again by hand the next time the content is published.
The job of the presentation algorithm is to determine exactly how the content is going to be organized as a document. The presentation algorithm produces a pure document domain version of the content.
 The organization of content involves several things:
The organization of content involves several things:
Ordering: At some level, content forms a simple sequence in which one piece of information follows another. Authors writing in the document domain typically order content as they write, but if they are writing in the subject domain, they can choose how they order subject domain information in the document domain.
Grouping: At a higher level, content is often organized into groups, which could be groups on a page or groups of pages. Grouping includes breaking content into sections or inserting subheads, inserting tables and graphics, and inserting information as labeled fields. Authors writing in the document domain typically create these groupings as they write, but if they are writing in the subject domain, you may have choices about how you have the presentation algorithm group subject domain information in the document domain.
Blocking: On a page, groups may be organized sequentially or laid out in some form of block pattern. Exactly how blocks are to be laid out on the displayed page is a media domain question, and something that may even be done dynamically. In order to enable the media domain to do this, the document domain must clearly delineate the types of blocks in a document in a way that the formatting algorithm can interpret and act on reliably.
Labeling: Any grouping of content requires labels to identify the groups. This includes things like titles and labels on data fields. Again, these are typically created by authors in the document domain, but are almost always factored out when authors write in the subject domain (most labels indicate the place of content in the subject domain, so inserting them is a necessary part of reversing the factoring out of labels that occurs when you move to the subject domain).
Relating: Ordering, grouping, blocking, and labeling cover organization on a two dimensional page or screen. But content also can be organized in other dimensions by creating non-linear relationships between pieces of content, including hypertext links and cross references.
The organization of content is an area where the document domain cannot ignore the differences between different media. Although the fact that a relationship exists is a pure document domain issue, how that relationship is expressed, and even whether it is expressed or not, is affected by the media and its capabilities. Following links in online media is very cheap. Following references to other works in the paper world is expensive, so document design for paper tends to favor linear relationships, while document design for the web favors hypertext relationships. As a result, you should expect to implement differential single sourcing and use different presentation algorithms for different media.
The presentation algorithm may be broken down into several useful sub-algorithms, each dealing with a different aspect of the presentation process. How you subdivide your publishing algorithm depends on your particular business needs, but it may benefit you to treat these operations as separate algorithms.
How content is linked or cross-referenced is a key part of how it is organized in different media, and a key part of differential single sourcing. We will look at the linking algorithm in detail in a future article.
Part of the presentation of a document or document set is creating the table of contents, index, and other navigation aids. Creating these is part of the presentation process. Because these algorithms create new resources by extracting information from the rest of the content, it is often easier to run these algorithms in serial after running the main presentation algorithm. This also makes it easier to change the way a TOC or index is generated without affecting other algorithms.
Many formats today contain embedded metadata designed for use by downstream processes to find or manage published content. One of the most prominent is HTML microformats which identify content to other services on the web, including search engines. This is a case of subject domain information being included in the output. Just as subject domain metadata allows algorithms to process content in intelligent ways as part of the publishing process, subject domain metadata embedded in the published content allows downstream algorithms (such as search engines) to use the published content in more intelligent ways.
If authors write content in document domain structures, they generally create public metadata as annotations on those document domain structures. But if they create content in the subject domain, the public metadata is usually based on the existing subject domain structures. In this case, the public metadata algorithm may translate subject domain structures in the source to document domain structures with subject domain annotations in the output.
This does not necessarily mean that the public metadata you produce is a direct copy of subject domain metadata you use internally. Internally, subject domain structures and metadata are generally based on your internal terminology and structures that meet your internal needs. Public terminology and categories (being more generic and less precise than the private) may differ from the ones that are optimal for your internal use. But because this is subject domain metadata (and thus rooted in the real world), there should be a semantic equivalence between your private and public metadata. The public metadata algorithm, therefore, not only inserts the metadata but sometimes translates it to the appropriate public categories and terminology.
In many cases, content written in the subject domain also includes many document domain structures. If those document domain structures match the structures in the document domain formats you are creating, the presentation algorithm merely needs to copy them to the document domain. In some cases, however, the document domain structures in the input content do not match those required in the output, in which case you must translate them to the desired output structures.
The synthesis algorithm determines exactly what content will be part of a content set. It passes a complete set of content on to the presentation algorithm to be turned into one or more document presentations.
The synthesis algorithm transforms content and data into a fully realized set of subject domain content. Sources for the synthesis algorithm include content written in the subject domain, document domain, or subject domain content with embedded management domain structures, and externally available subject data which you are using to generate content.
Content that contains management domain metadata, generally used for some form of single sourcing or reuse, does not represent a final set of content until the management domain structures have been resolved. In the case of document domain content, processing the management domain structures yields a document domain structure which may then be a pass-through for the presentation algorithm. In the case of the subject domain content, processing management domain structures yields a definitive set of subject domain structures which can be passed to the presentation algorithm for processing to the document domain.

We noted above that you can use differential presentation to do differential single sourcing where two publications contain the same content but organized differently. If you want two publications in different media to have differences in their content, you can do this by doing differential synthesis and including different content in each publication.

The synthesis algorithm can involve a number of sub-algorithms, depending on the kind of content you have and its original source.
If your content contains management domain include instructions, such as we identified in discussing the reuse algorithm, these must be resolved and the indicated content found and included in the synthesis.
As we noted, you can also include content based on subject domain structures, without any management domain include instructions. Such inclusions are purely algorithmic — meaning that the author does not specify them in any way. It is the algorithm itself that determines if and when content will be included and where it will be included from. The inclusion algorithm also performs this task.
If your content contains management domain conditional structures (filtering) they must be resolved as part of the synthesis process. In most cases, you will be using the same set of management domain structures across your content set, so maintaining your filtering algorithm separately makes it easier to manage.
Again, note that you may be filtering on subject domain structures as well (or instead of) on explicit management domain filtering instructions. Such filtering is, again, purely algorithmic, meaning that the author has no input into it. The filtering algorithm is then wholly responsible for what gets filtered in and out and why.
It is important to determine the order in which inclusion and filtering are performed. The options are to filter first, to include first, or to include and filter iteratively.
Generally, you want the filtering algorithm to run before other algorithms in the synthesis process so that other algorithms do not waste their time processing content that is going to be filtered out. On the other hand, if you run the filtering algorithm before you run the include algorithm, any necessary filtering on the included content will not get executed.
Doing inclusion before you filter addresses this problem, but creates a new one. If you include before you filter, you may include content based on instructions or subject domain structures that are going to be filtered out. This could then leave you with a set of included content that was not supposed to be there, but no easy way to identify that it does not belong.
The preferred option, therefore, is to run the two algorithms iteratively. Filter your initial source content. When you filter in an include instruction, immediately execute the include and run the filtering algorithm on the included content, processing any further filtering instructions as they are filtered in.
The rules based approach to content processing previously described in this series makes this kind of iterative processing relatively easy. You simply include both the filtering and inclusion rules in one program file and make sure that you submit any included content for processing by the same rules the moment it is encountered.
match includeprocess content at hrefcontinue
In some cases you may wish to extract information from external sources to create content. This can include data created for other purposes, such as application code, or data created and maintained as a canonical source of information, such as a database of features for different models of a car. We will look at the extraction and merge algorithms in a later article.
The synthesis algorithm will produce a collection of content, potentially from multiple sources. This collection is then the input to the presentation algorithm. For the presentation algorithm to do its job, it needs to know all of the content it has to work with. In particular, the TOC and index algorithms and the linking algorithm need to know where all the content is, what it is called, and what it is about. They can get this information by reading the entire content set, but this can be slow, and perhaps confusing if the structure is not uniform. As an alternative, you can generate a catalog of all the content that the synthesis algorithm has generated which can then be use by these and other sub-algorithms of the presentation algorithm to perform operations and queries across the content set.
When we create authoring formats for content creation, we should do so with the principal goal in mind of making it as easy as possible for authors to create the content we require of them. This means communicating with them in terms they understand. This may include various forms of expression that need to be clarified based on context before they can be synthesized with the rest of the content. This is the job of the resolve algorithm. Its output is essentially a set of content in which all names and identifications are in fully explicit form suitable for processing by the rest of the processing chain.
Content written in the subject domain is not always written in a fully realized form. When we create subject domain structures, we put as much emphasis as we can on ease of authoring and correctness of data collection. Both these aims are served by using labels and values that make intuitive sense to authors in their own domain. For example, a programmer writing about an API may mention and markup a method in that API using a simple annotation like this:
To write a Hello World program, use the {hello}(method) method.
In your wider documentation set, there may be many APIs. To relate this content correctly in the larger scope you will need to know which API it belongs to. In other words, you need this markup:
To write a Hello World program, use the {hello}(method (GreetingsAPI)) method.
The information in the nested parentheses is a namespace. A namespace specifies the scope in which a name is unique. In this case, the method name hello might occur in more than one API. The namespace specifies that this case of the name refers to the instance in the GreetingsAPI.
Rather than forcing the programmer to add this additional namespace information when they write, we can have the synthesis algorithm add it based on what it knows about the source of the content. This simplifies the author’s task, which means they are more likely to provide the markup we want. (It is also another example of factoring out invariants, since we know that all method names in this particular piece of content will belong to the same API.)
As we have seen, structured writing algorithms are usually implemented as set of rules that operate on structures as they encounter them in the flow of the content. Since each algorithms is implemented as a set of rules, it is possible to run two algorithms in parallel by adding the two sets of rules together to create a single combined set of rules that implements both algorithms at once.
Obviously, you must take care to avoid clashes between the two sets of rules. If two set of rules act on the same structure, you have to do something to get the two rules that address that structure to work together. (Different tools may provide different ways of doing this.)
Sometimes, though, one algorithm needs to work with the output of a previous algorithm, in which case, you need to run them in serial.
In most cases, the major algorithms (synthesis, presentation, formatting, encoding, and rendering) need to be run in serial, since they transform an entire content set from one domain to another (or from one part of a domain to another). In many, but not all, cases the sub-algorithms of these major algorithms can be run in parallel by combining their rule sets since they operate on different content structures.
The biggest issue for every algorithm in the publishing chain is consistency. Each step in the publishing chain transforms content from one part of the content spectrum to another, generally in the direction of the media domain.
The more consistent the input content is, the easier it is for the next algorithm in the chain to apply a simple and reliable process to produce consistent output, which in turn simplifies the next algorithm in the chain, making it more reliable.
Building in consistency at source is therefore highly desirable for the entire publishing algorithm. This presents an interesting problem, because good content by its nature tends to be diverse, and therefore less consistent and more prone to exceptions. It is the stuff that does not fit easily into rows and columns.
One approach to this problem is to write all the content in a single document domain language such as DocBook. Since all the content is written in a single language it is theoretically completely consistent and therefore should be easy to process for the rest of the tool chain.
The problem with this is that any document domain language that is going to be useful for all the many kinds of documents and document designs that many different organizations may need is going to contain a lot of different structures, some of which will be very complex and most of which will have lots of optional parts. This means that there can be thousands of different permutations of DocBook structures. A single formatting algorithm that tried to cover all the possible permutations could be very large and complex—and likely very hard to maintain.
The alternative is to have authors write in small, simple subject domain structures that are specific to your business and your subject matter. You would then transform these to a document domain language using the presentation algorithm. This document domain language could still be DocBook, but now that you control the DocBook structures that are being created by the presentation algorithms, you don’t have to deal with all the complexities and permutations that authors might create in DocBook, just the structures that you know your presentation algorithm creates.
These subject domain documents would have few structures and few options and therefore few permutations. As a result, the presentation algorithms for each could be simple, robust, and reliable, as well as easy to write and to maintain. You could also do differential single sourcing by writing different presentation algorithms for each media or audience.
The trade-off, of course, is that you have to create and maintain the various subject domain formats you would need and the presentation algorithms that go with them. It’s a trade-off between several simple structures and algorithms and a few complex ones.

Deflection points in the content, points in which the reader’s “next” may not be the thing that comes next in the linear order of the work. To support information foraging, we may need to deflect to other content or to a different way of finding information using linking algorithms.
1600 Amphitheatre Parkway, Mountain View, CA 94043
+1 650-253-0000
prothemes.net@gmail.com
Daily: 9:00 am - 6:00 pm
Sunday: Closed