Editor’s Note: Mark Baker continues his ongoing series on Structured Writing with a deep dive into how writing in the media domain takes advantage of structure to render abstract concepts in concrete forms. Discover more in his previous pieces, which attempt to define structured writing, and also describe the three domains of content structure.
The media domain is the structured writing domain in which the structures relate to the media in which the content is displayed. Such content is often considered “unstructured,” but this really means “not structured in a way that is currently useful to me.” In fact all content has structure, and we can actually find the patterns and techniques of all forms of structured writing in the media domain. This makes it a good place to study the fundamentals of structured writing.
At its most basic, a hand guiding the pen over paper or chisel over stone is working in the media domain through  direct physical interaction with the media. But this is not structured writing in the sense we mean it here. No computable structures are involved because no computer is involved.
direct physical interaction with the media. But this is not structured writing in the sense we mean it here. No computable structures are involved because no computer is involved.
We don’t do a lot of physical writing these days. Mostly, we interact with computers, which then drive machines that interact with physical media in the form of screens, paper, or engraving surfaces. The closest you can get to pen and paper in the computer world is to use a paint program, select the pen tool, and use your mouse or stylus to write your text. This records the text as a matrix of dots. You can then print those dots to paper. Those patterns of dots are text characters only in the sense that the patterns are recognizable as characters to the human eye. The computer has no idea they are characters.
 This represents a pretty inefficient way to write. You can work faster if you use the paint program’s text tool. This allows you to type letters on the keyboard. However, those letters are still recorded as a matrix of dots, not as characters, so you can’t go back and edit your text as text, only as dots. (This type of program is technically known as a raster graphics application, where the word “raster” means an array of pixels or matrix of dots.)
This represents a pretty inefficient way to write. You can work faster if you use the paint program’s text tool. This allows you to type letters on the keyboard. However, those letters are still recorded as a matrix of dots, not as characters, so you can’t go back and edit your text as text, only as dots. (This type of program is technically known as a raster graphics application, where the word “raster” means an array of pixels or matrix of dots.)
To work more efficiently, you need to move away from dots and start working in a program that records characters as characters. You could go to a text editor, which records characters as characters, but a text editor does not keep any formatting information (unless you create markup — but that would be getting ahead of ourselves). For most publishing purposes, plain text is inadequate. We need to maintain the ability to format the document.
A vector graphic program creates graphics as a collection of objects (“vector” meaning the mathematical representation of a shape or line). For example, it allows us to create a circle as a shape, described mathematically in computer memory, rather than as a matrix of dots. Rather than recording an actual circle, the program records an abstraction of a circle: the essential properties needed to reproduce an actual circle on a media, such as its center, diameter, and line weight. The computer then lets you manipulate that abstraction as an object, only rendering it as actual dots when the graphic is displayed on screen or paper.
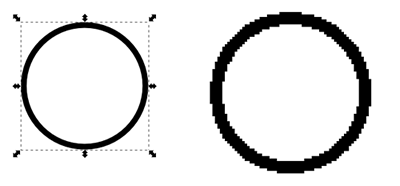
A circle as an object, displayed in a vector graphics program (Inkscape), left, vs. a circle as a set of dots in a raster graphics program (Paint), right
In a typical graphics program, a shape is rendered into dots on screen instantly as you draw or edit the shape. Nonetheless, the computer stores data that describes the shape, not a circular pattern of dots, as it would in a paint or photo editing program. This is an instance of what in structured writing circles is called “separating content from formatting”. The mathematical abstraction of a circle is the content; the dots that represent it on screen are the formatting, or rather, the result of applying formatting to the object.
To give you some idea of how a circle might be represented as an object, here is a sample piece of Java code for creating a circle:
Circle circle = new Circle(); circle.setCenterX(100.0f); circle.setCenterY(100.0f); circle.setRadius(50.0f);
This code creates a new circle object and specifies three values that you would need to draw a basic circle, an X and Y coordinate for the center of the circle, and the radius. (The object actually needs more fields, like line width, color, and fill, but I have simplified the example for size and clarity.)
When the computer displays or prints the vector graphics file, a rendering algorithm turns those objects into a matrix of dots on the current media, using more dots for higher resolution media, and perhaps substituting gray dots for colors when printing on a black and white device.
One way that this can be done is using PostScript, which works by moving a virtual pen over a virtual surface, recording dots as it goes. So the description of a circle object in terms of location and radius is turned into a set of instructions for moving that virtual pen:
100 100 50 0 360 arc closepath stroke
This says, “draw an arc whose center is at coordinates 100, 100, and whose radius is 50, starting at degree 0 and proceeding to degree 360”. This is the algorithm guiding a virtual pen over virtual paper, just as the author we first described moved a real pen over real paper.
If representing the circle as an object creates an abstraction of “circle” in the media domain, this bit of PostScript code takes that abstraction (a circle as a set of coordinates) and (in concert with the underlying graphics driver) makes it concrete again (dots on a media).
The point here is not to understand the code, but to see that by creating a more abstract form of the content, we can make it easier to work with, and that we can use algorithms to render it back into concrete form. All of structured writing comes down to finding better ways to represent content for a particular purpose (more efficient, more versatile, more verifiable, more precisely constrained) and ways to transform those representations, eventually, into dots on a screen or paper so that the content can be read.
We will see this pattern as we look at structured writing across the three domains. Rather than storing the image of the document to be printed, the computer stores an abstraction of the document which consists of raw text combined with (or, in some cases, replaced by) additional pieces of information, commonly called metadata. You can then use this metadata to manipulate the content in whatever way you need, and also to drive algorithms to convert it back into a concrete media domain representation that can be displayed to readers.
Adding metadata to text creates structures that the computer can create, store, and manipulate. It is useful to think of structures as objects, just as we think of the representation of a circle in a vector graphics program as an object. And indeed, a vector graphics program lets you create a text object.
A text object is a rectangular area that contains characters. It has numerous properties, such as margins, background and foreground colors, the text string, and the font face, size, and weight used to display that text, and in this example from InkScape:

A text object in a vector graphics program, with object properties shown.
Abstracting out font information
A vector graphics program displays text in a chosen font. If your change the value of the text object’s font attribute, it will immediately redraw the text in the new font. The shapes of the individual letters in the font are required information for rendering the text object in the media domain. However, they are not stored as part of the text object. Whereas the representation of the text in the paint program includes the shape of the letters, in the vector graphics program it does not. That information has been factored out.
The shape of the characters (technically, “glyphs”) that make up the font are stored separately in font files. Font files consist of a set of shape objects that describe each glyph, together with metadata such as the name of the font and the name of each glyph. To actually display the text block on screen, the graphics program (or rather the graphics system API to which it delegates this task) combines information from the font file with information from the text object by matching the metadata to find the right font and character, and then drawing the appropriate glyph on the current media.

The vector graphic text object factors out letter shapes to a separate font file.
We see this pattern over and over again in structured writing. To simplify the objects that we create to store our content, we take part of the information needed to do the final rendering, like the font, and move it to a separate file. By moving out information that is constant for a given application (the shape of a capital F is the same for all capital F’s for text in a given font), we simplify the format of the information we are preparing and keep the downstream presentation more consistent.
Adding more structure to content means adding more metadata to it. But if we just kept adding metadata, it would very quickly overwhelm the content. So whenever we can, we carve some metadata off into separate files and create rules for pulling it back in when it is time to publish the content.
Whether it is, “the capital F will always be this shape” or “the list of ingredients will always have the ingredient name aligned left and the quantity aligned right”, filtering out these invariant rules into a separate file is a key part of structuring content.
Thus designing a content structure, regardless of the domain you choose to work in, essentially consists of identifying the places in the content where we can separate out these invariant properties into separate structures, and where doing so will contribute to the core goal of structured writing, which is to make content better.
Using constraints to improve efficiency
Writing a document in a vector graphics program is certainly better than trying to write it in a paint program, but it is hardly ideal for writing long documents. This is why most of us use tools designed specifically for writing documents.
A vector graphics program knows nothing about the document domain. It works purely in the media domain, and pretty much lets you put shapes and text boxes anywhere you like. This give you enormous freedom, but it also makes you do a lot of extra work if what you want to create is a typical document that is basically one long text flow with some headings and graphics thrown in.
Word processors and desktop publishing programs make it easier to create documents by introducing some document domain constraints, as well as some higher-level tools for managing large text flows. A document consists of a series of pages that have margins and contain text flows. Text flows are made up of blocks (paragraphs, headings), inside of which text flows. Common features like tables are supported as objects than can exist in text flows. Text flows may cross page boundaries. New pages are created automatically as text expands.
Pages, paragraphs, headings, and tables, are all document domain objects. Rather than working on a blank slate, as you do in a graphics program, you are now working within the constraints of these document domain objects. These constraints remove or constrain decision about positioning of elements, which makes creating documents faster and more consistent. As we said, structured writing is about making content that obeys constraints, and these basic document domain constraints are the next step in that journey.
These constraints are not without their negative consequences. You always give up something when you impose a constraint. Certain page layout effects are difficult or impossible to achieve in Word or FrameMaker because you have given up some of the liberty of a vector graphics program. (You also gave up some liberty in moving from raster to vector graphics, which is why photo editing, which requires adjusting individual pixels, is still done in raster rather than vector format.) When your impose constraints on content, you must understand the tradeoff you are making and what the costs are on both sides of the ledger.
But while they make authoring easier by introducing document domain constraints into the program, both word processors and especially desktop publishing programs still live in in the media domain. While the programs create some basic document domain objects under the surface, the author sees and interacts with the media domain representation of those objects on their screen. And the way that these programs enable the writer to distinguish one block of text from another is almost entirely by applying formatting styles. The document domain objects they provide are just enough to give the author something to hang media domain styles on.
Enabling the media domain
Providing the author with the ability to work in the media domain was at the heart of the desktop publishing revolution. For centuries, scribes worked directly in the media domain, using pen and ink to inscribe words and pictures on paper or velum. With the printing press, however, authors no longer worked directly in the media domain. While authors still directly placed ink on paper, at first by pen and then by typewriter, they no longer prepared the final visual form of the content. That would be created later by the typesetter.
To tell the typesetter how to create the final visual form, document designers added additional instructions (metadata) to the author’s manuscript. The designers did this using typesetter’s marks, and the process was called “marking up” the document. We still use “marking up” to describe how structured writing is done today. The M in XML stands for Markup. (But modern structured writing does not always have such a clear cut distinction between text and markup as this usage implies, as we shall see.)
The writer preparing a manuscript for typesetting worked in the document domain, indicating basic document structures like paragraphs, lists, and titles, without any indication of how they should look in print. The designer then wrote a set of instructions for applying formatting to those structures — a formatting algorithm. Then the typesetter executed that algorithm by setting the type which the printer then used to print final output. (Here is that same pattern again — two steams of objects, merged by an algorithm to produce a new stream of objects.)

An example of typesetting markup on a physical manuscript.
We do the same thing today when we create an HTML page and specify a CSS stylesheet to supply the formatting instructions. The browser executes those instructions to render the content on screen or paper.
Actually, we are getting ahead of ourselves here. A better analogy to old style typesetters marks is an HTML page with the styles specified inline.
<p style="{font-family: serif; font-weight: bold; font-size: 12pt}">
You can see that this markup is very similar to the old typesetter’s marks in the illustration above.
Theoretically, a document designer could add those inline styles after the author had written the original HTML, but separating those tasks was not the intent of the desktop publishing movement. The intent was to combine the job of designer and writer into one, effectively moving the author from working in the document domain to working in the media domain.
The inefficiency of applying styles to every element soon became apparent, however. Stylesheet mechanisms were devised to separate the media domain elements of a document from the document domain elements. But using styles rather than direct formatting does not mean that you have moved from working in the media domain to working in the document domain. It just means that you have moved from working in an unstructured way in the media domain to working in a structured way in the media domain.
The set of document domain objects in a typical word processor is so small that it does not even distinguish between a heading and a list item. Both are just paragraphs with different styles applied. What distinguishes them is not what type of object they are, but what styles are applied to them. (The use of the word “paragraph” in these programs has nothing to do with its meaning in the study of composition. “Block” would be a better word.)
Actually, it is not quite so clear cut as that. While most DTP and word processing programs create lists as paragraphs with styles applied, rather than separate list objects, they do provide interface controls to create lists as if they were objects. In this respect, they work similarly to paint programs that let you draw shapes as objects that are resizable until you release your mouse and then become just dots. You can create a list as an object in these programs, but the result is just a set of styled paragraphs, not a permanent list object.
This sort-of-is/sort-of-isn’t-an-object approach pretty accurately describes how many authors think about what they do when they use these programs. Sometimes they think about creating document domain objects and sometimes simply about formatting. They don’t, of course, make the analytical distinction between media domain and document domain, but they clearly sometimes think “make a paragraph” and sometimes “insert a blank line”. Sometimes they think about creating a numbered list. Sometimes they just type a number at the beginning of a line and expect the application to format it appropriately.
Being too strictly object oriented in how a document is created could slow the writer down by forcing them to think in terms that are not natural to them. Thus these programs — Word much more so than FrameMaker — let the author do it whatever way seems natural to them.
But while being fuzzy about this can make every-day writing tasks less mentally demanding, it can also have unwelcome consequences when tackling longer documents or more varied or complex publishing scenarios. Word’s difficulties with maintaining list numbering are well documented. Frame does a better job of this kind of thing, but has a steeper learning curve because its greater reliability in handling these things comes at the expense of forcing the writer to think more about what kind of object they are creating.
Word processing and desktop publishing, therefore, tend to straddle the boundary between the document and media domains, with authors thinking partially in document domain terms and partially in media domain terms, and the applications creating and storing objects and structures from both domains. In many cases, these applications offer both a document domain way and a media domain way to do something, which simplifies the authoring thought process but produces files that are often unreliable for downstream processing, or that require significant cleanup if some general change of style or publication to a new media is required.
The only way to solve these problems cleanly is to move writers, and the files they create, out of the media domain entirely. The next stop on that path is the document domain.