Editor’s note: The latest in Mark Baker’s series on Structured Writing describes how the three domains of content work to structure content. Read his first article for more on how Mark defines structured writing.
From ideas to dots
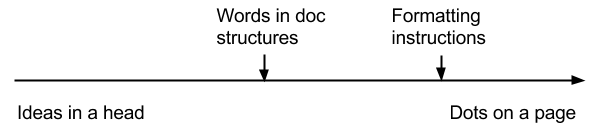
 The process of creating and delivering content consists of translating ideas (stuff someone thinks or knows) into concrete physical form that can be read (dots of ink or pixel on a page or screen). The writing and publishing process is all about how we get from ideas in a head to dots on a page.
The process of creating and delivering content consists of translating ideas (stuff someone thinks or knows) into concrete physical form that can be read (dots of ink or pixel on a page or screen). The writing and publishing process is all about how we get from ideas in a head to dots on a page.
In the simplest case, an author writes down their ideas with pen and paper. The entire translation from ideas to dots takes place in the author’s head. The content is recorded directly in the final physical form.
Recording content directly in physical form is rare these days. In most cases, the content is recorded earlier in the process, and software takes it from the place it is recorded to the final rendering on paper or screen.
Word processing and desktop publishing software, and various approaches to structured writing all establish a point in this process from ideas to dots where the content will be recorded by the author, and then provide algorithms to complete the movement from that point to dots on a page.The differences between them lie in how and where in the process content recording takes place, and the kinds of algorithms they provide for processing it beyond that point.
When you use a word processor, you record content using abstract document structures — lists, tables, paragraphs. Separately, you can define styles which are then applied to the content before it is sent to a printer to be rendered into ink on paper.
What is notable about this process is that the content and the styles are defined separately. The author creates two different kinds of data: content and styling instructions. These two streams are then fed to the software to drive the final rendering.
This combination of multiple streams of data and instructions is a common feature of any system that records content before the dots stage. All content must eventually be displayed as dots and way you capture content that does not specify the position of dots, requires instructions — algorithms — for turning the recorded format into the exact locations of dots on paper or screen.
In a modern word processor, the software can take content and style instructions and combine them on the fly to create a WYSIWYG display, creating the illusion that the author is producing the final rendered output directly. As we will see, the earlier we record the content, the more difficult this becomes.
What we commonly call “structured writing” is simply a process of moving the recording of the content still earlier in the process from ideas to dots. What this implies, of course, is that WYSIWYG word processing is not the opposite of structured writing. It is actually just a point on the structured writing continuum: a point quite close to dots on a page.

Other approaches to structured content simply move the moment at which content is recorded closer to the ideas-in-a-head end of the scale.
Of course, the text itself always conveys the author’s ideas, at least as well as the author is capable of expressing them. What is at issue here is what part software plays in the process by which the ideas in the author’s head make the journey to dots on a page. That role may as simple as allowing different dots to be rendered on different surfaces from the same source files, or the software may play an active role in shaping and organizing the text.
The three domains
We can divide this journey from ideas to dots into three domains: the subject domain, the document domain, and the media domain.
Let’s suppose that an author is writing a recipe for chicken noodle soup. They start out with the idea of a soup with chicken and noodles. This is an idea about the subject matter and not yet any form of content.
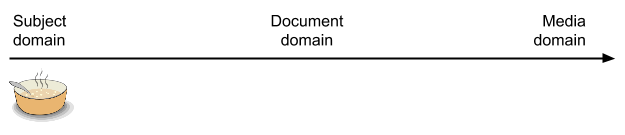
They then decide to give the dish the name “Chicken Noodle Soup.” Unlike the soup itself, the name is content. However, it is not yet part of a document. It is a piece of data in the subject domain.
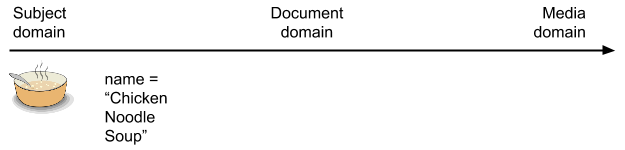
Then the author decides to write down the recipe for Chicken Noodle Soup. They will probably use the name of the dish as the title of the recipe. A title is an object in the document domain. Documents have titles. This is a particular kind of document, however — a recipe. While a recipe is a document type, it is a document type with a strong relationship to the subject domain — the subject of dishes and their preparation.
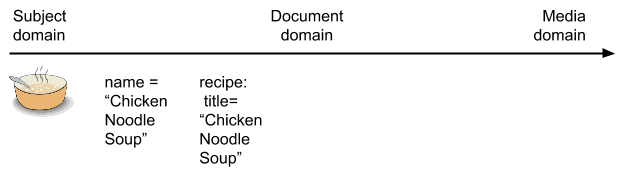
As the process continues, some format for publishing the recipe is chosen. This might be HTML. HTML is a markup language in the document domain. That is, it contains markup for typal document structures such as title, paragraphs, and lists. To express the title of the recipe in HTML, we turn the declaration of the title of the recipe into a declaration about an HTML heading level:
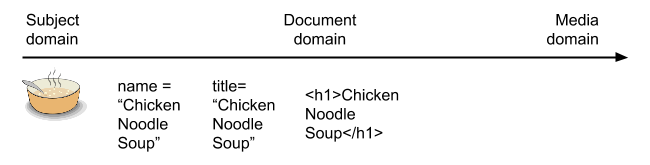
In doing this, we have greatly weakened the association with the subject domain. At this stage we know that “Chicken Noodle Soup” is the title of a web page, not that it is the title of a recipe, and not that it is the name of a dish. However, we have also made it more specific what type of document this is: a web page.
In deciding that it is a web page, we have also started to bring in something of the media domain. HTML is by no means exclusive to a single media. It can be use to create web pages, help platforms, mobile applications, and even printed pages. At the same time, it includes a number of presumptions about the media domain in which the document will be displayed.
If you follow modern practice, however, your HTML should not include any specific information about how the document will be rendered — what fonts will be used, how big the margins will be, etc. We move the content further into the the media domain by creating a CSS stylesheet that specifies these matters. (This is one of those cases of two converging streams of information that I mentioned at the beginning.)
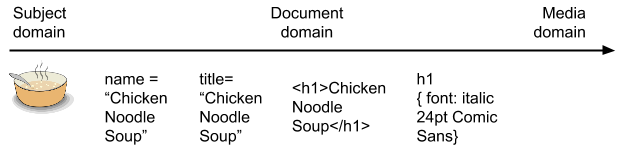
Adding the CSS moves the entire package further into the media domain. Notice, however, that in this case, all of the document domain information in the HTML format has been retained. The movement from the subject domain through the document domain into the media domain does not have to mean that information from an earlier domain has to be thrown away as you add information from the later domains. For instance, HTML5 microformats allow you to retain subject domain information all the way into the user’s browser. Traditional publishing techniques tended to throw away subject domain information as the process advanced. Today, that information is more likely to be retained as long as possible. (One of the implications of the term “intelligent content”.)
When the resulting page is loaded into a browser, dots are painted on the screen in the appropriate shape.
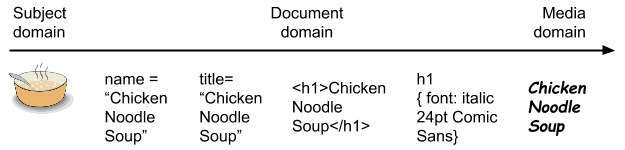
This process involves translating the document and media domain information in the HTML and CSS into the graphics primitives of the platform on which the content is displayed — basically lighting up dots on a screen or printing dots on paper. This final step will destroy all document and subject domain information, but since the browser retains the HTML source, any information that has reached that point is available to code running in the browser.
Declarative vs. Imperative
As we move from the subject domain through the document domain and into the media domain, we will find that we are moving from the declarative to the imperative. A declarative statement simply says what something is. An imperative statement gives an instruction. Ideas in the subject domain are purely declarative. Dots are created by purely imperative software instructions.
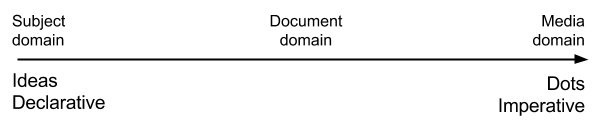 As we proceed from the subject domain to the media domain, therefore, we are continually converting declaratives into imperatives. For example, the CSS rule:
As we proceed from the subject domain to the media domain, therefore, we are continually converting declaratives into imperatives. For example, the CSS rule:
h1 { font: italic 24pt Comic Sans}
turns the more declarative HTML <H1> tag, which simply declares that a piece of content is a level one heading, into a specific set of instructions about fonts.
As we proceed from ideas to dots, the content contains fewer declarations about the subject matter and more declarations about the structure of a document, and then a little less about the structure of a document and a little more of an instruction to a rendering process. By the time we reach the HTML stage, we no longer have any declaration that associates the words with soup (unless we use microformats). There is only an document structure (this is a major heading, this is a list), which then becomes more concrete at each of the following stages until it is just instructions for placing dots on a surface.
When we look at formats used to record content at each of these stages, we will find that in the subject domain the format is entirely declarative. In the document domain we typically find a mix of declarative and imperative elements. In the media domain, we have only imperatives (though some imperatives may be declarative in form).
The implication is that as we move the point of recording earlier in the process, we are actually doing the opposite: we are removing imperatives and substituting declaratives. We are turning instructions about how a document should look into declarations about how the document is organized or what the content is about.
One of the classic descriptions of structure writing is “separating content from formatting.” This is how we separate content from formatting, by replacing instructions about how to format the content into declarations about the structure or subject matter of the content. If you have wondered exactly how content gets separated from formatting, and what that looks like in practice, this illustration should clarify how any movement away from the media domain towards the document domain or from the document domain towards the subject domain is a case of further separating content from formatting. And it should emphasize that the process can look very different depending on where you start from and where you are going.
Why is it valuable to move the point of content creation back from the media domain into the document domain or the subject domain, from the declarative to the imperative? There are several reasons:
- Declaratives give you choices. A declaration about the structure of a document or the subject of a sentence does not force you to display it in a particular way. An imperative, on the other hand, is an instruction that has to be obeyed. Moving from the declarative to the imperative is a process of making choices. Moving from the imperative to the declarative is a process of postponing choices.
- Declaratives can be constrained. We defined structured writing as the act of creating content with certain constraints. Declaratives can be constrained much more easily and with much greater precision than imperatives. Declaratives can also be audited and validated with greater precision than declaratives.
- Declaratives are easier to write. For an author to create declaratives, they need only a know the subject matter and the format of the declarations. For an author to create imperatives requires that they understand the language and effect of the instructions. In the case of embedded algorithms, it requires that the user understands the language of those algorithms.
We will look at these advantages, and the many different content processing algorithms you can enable with a more declarative content structure, in later article