
Image by Klesters on flickr.com, No Changes, License
The reuse of content in different contexts has become one of the main drivers of structured writing, particularly in the form of widespread adoption of DITA. The principle motivations for reusing content are to reduce costs (by avoiding creating the same content multiple times and to ensure consistency or compliance with regulations (by always drawing content from an approved source).
Content reuse is not one technique, but a collection of many techniques. There are therefore several reuse algorithms each of which requires specific content structures in the subject and document domains.
The simplest content reuse technique is to cut and paste content from one source to another. This approach is quick and easy to implement, but it creates a host of management problems. So when people talk about content reuse they generally mean any and every means of reusing content other than cutting and pasting.
Reusing content, then, really means storing a piece of content in one place and inserting it into more than one publication by reference. “Reusing” suggests that this activity is somewhat akin to rummaging through that jar of old nuts and bolts you have in the garage looking for one that is the right size to fix your lawnmower. While you can do it that way, that approach is neither efficient nor reliable. The efficient and reliable approach involves deliberately creating content for use in multiple locations. When you deliberately create content for reuse, you need to place constraints on the content to be reused and the content that reuses it, and that puts you in the realm of structured writing.
Fitting pieces of content together
If you are going to create one piece of content that can be used in many outputs, you have to make sure it fits in each of those outputs.
This is not something you worry about when you cut and paste. You can cut any text you like, paste it in anywhere, and edit it to fit if need be. But if the content you want to use is used in other places, you can’t edit it to fit because that might cause it to no longer fit in the other places. For reuse to work, the content must be written to fit in multiple places. In other words, it has to meet a set of constraints that will allow it to fit together with other pieces of content in multiple places.
There are seven basic models for fitting pieces of content together:
- Common into variable
- Variable into common
- Variable into variable
- Common with conditions
- Factor out the common
- Factor out the variable
- Assemble from pieces
Common into variable
In the common into variable case, you have a common piece of content that occurs in many places. This could mean it occurs in many documents or in many places in the same document, or both.
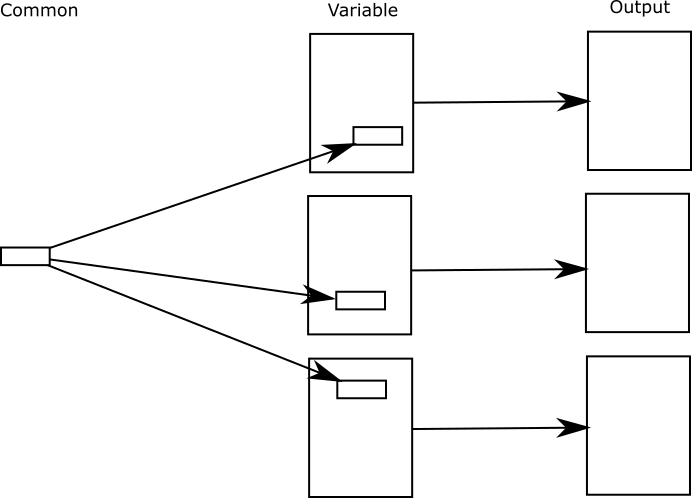 For instance, if there is a common safety warning that must appear on all dangerous procedures, each individual procedure is the variable part and and the standard warning is the common part.
For instance, if there is a common safety warning that must appear on all dangerous procedures, each individual procedure is the variable part and and the standard warning is the common part.
We looked at an example of this in the article on the management domain.
procedure: Blow stuff up
>>>(files/shared/admonitions/danger)
step: Plant dynamite.
step: Insert detonator.
step: Run away.
step: Press the big red button.
To ensure that the included content will always fit, you need to make sure that there is a clear division of responsibilities between the common content and each of the documents it will be inserted into. The inserted content should give the safety warning, the whole safety warning, and nothing but the safety warning. Each document that includes it should include it in the required place in the procedure structure.
Variable into common
In the variable into common case, you have a single document that will be output in many different ways by inserting variable content at certain locations.
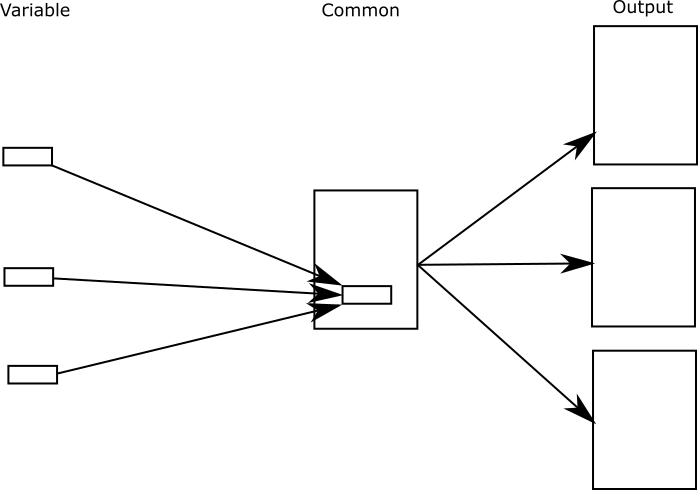 For instance, if you are writing a manual to cover a number of car models you can factor out the number of seats each model has.
For instance, if you are writing a manual to cover a number of car models you can factor out the number of seats each model has.
The vehicle seats >($seats) people.
This is the fixed content that will occur in all manuals, with the number of seats pulled in from an external source. Let’s say we have a collection of vehicle data that is stored in a structure like this:
vehicles:
vehicle: compact
seats: four
colors: red, green, blue, white, black
transmissions: manual, CVT
doors: four
horsepower: 120
torque: 110 @ 3500 RPM
vehicle: midsize
seats: five
colors: red, green, blue, white, black
transmissions: CVT
doors: four
horsepower: 180
torque: 160 @ 3500 RPM
Then we write the algorithm to process the insert so that it queries this structure.
match insert with variable where variable = $doors
$number_of_doors = vehicles/vehicle[$model]/doors
output $number_of_doors
All these insert and query mechanisms are pseudocode, of course. Exactly how things work and exactly how you delineate, identify, and insert content vary from system to system.
With the variable into common technique, you create a common source by factoring out all the parts of the different outputs that are not common. This is, in some ways, the inverse of the usual pattern of factoring out invariants: we are actually factoring out the variants. But really, it amounts to the same thing. We are factoring variants from invariants. The only real difference between this and the common into variable is whether the common parts are embedded in the variable parts or vice versa. Either way, we still end up with two artifacts: the variable piece or pieces and the common piece or pieces.
Variable into variable
Variable into variable is a variation on common into variable in which you can make a wholesale change of the common elements that you are pulling into a set of variable documents.
For example, suppose you decide to market your product line to a new market. The new market has different safety regulations, which means you need to insert a different standard warning into all your manuals. In this case, you want to swap out the common elements used in your home market and substitute the common elements for the foreign market.
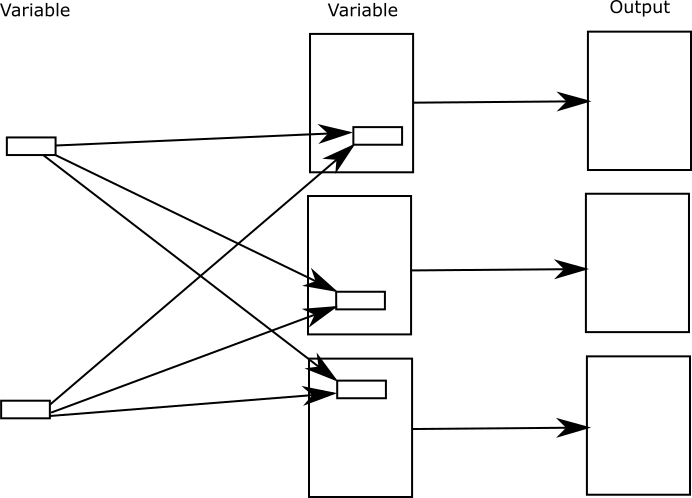
Here we need to talk about how we identify the content to be inserted. In the common into variable example, we inserted the content of a file that contains a standard warning. But this approach is fragile. You can’t reorganize your files without breaking reuse, and you almost always need to reorganize your files eventually. Plus, it forces you to have every piece of reusable content in a separate file, which often proves inefficient.
This approach simply does not work for variable into variable, because this model requires loading a different file, which is difficult when the content specifies a particular file name to import.
As always in structured writing, we look for a way to factor out the problematic content. So here we look for a way to factor out the file name and replace it with something else.
The most basic way to factor out the file name is to give the content of the file an ID, and use the ID to identify the content in a location independent way. Here is the warning file with the ID #warn_danger added:
warning:(#warn_danger)
title: Danger
Be very very careful. This could kill you.
We can then insert the warning into our procedure by referring to that ID.
procedure: Blow stuff up
>>>(#warn_danger)
step: Plant dynamite.
step: Insert detonator.
step: Run away.
step: Press the big red button.
The responsibility for locating the warning has now been shifted from the content to the algorithm.
match insert with ID
$insert_content = find ID in $content_set
output $insert_content
This is a constant pattern in structured writing. When it comes to locating resources, you want to move that responsibility from the content to the algorithm. Not only is it easier to update the locations, but you have far more options for storing and managing your content, since algorithms can interact with a variety of systems in sophisticated ways, rather than just storing a static address. It also means you can make wholesale changes in how your content is stored without having to edit the content itself.
But, the synthesis algorithm needs some way to resolve the ID and find the content to include. In many cases, a content management system is used to resolve the ID. In other cases it is as simple as the algorithm searching through a set of files to find the ID or building a catalog that points to the files that contain IDs.
To do variable into variable reuse in a system that uses IDs, you simply point the synthesis algorithm at a different set of files that contain the same IDs, but attached to different content. So if your foreign market requires a different warning, you can create a file like this:
warning:(#warn_danger)
title: Look out!
Pay close attention. You could really hurt yourself.
By telling the build to search this file for IDs rather than the file with the domestic market warning, you automatically get the the foreign warning rather than the domestic one.
Another way to do this is with keys. Instead of assigning an ID directly to the content, the keys approach use an intermediate lookup table to resolve keys to particular resources.
So in this case we have the warning in a file called files/shared/admonitions/domestic/danger with the following content (no ID):
warning:
title: Danger
Be very very careful. This could kill you.
And we have the procedure which includes the warning via a key:
procedure: Blow stuff up
>>>(%warn_danger)
step: Plant dynamite.
step: Insert detonator.
step: Run away.
step: Press the big red button.
(I am using # to denote IDs and % to denote keys. This is purely arbitrary and has nothing to do with how they work. Different systems will denote IDs and keys in different ways.)
To connect the key to the warning file, we then create a key lookup table:
keys:
key:
name: warn_danger
resource: files/shared/admonitions/domestic/danger
When the synthesis algorithm processes the procedure, it sees the key reference %warn_danger and looks it up in the key lookup table. The key lookup table tells the algorithm that the key resolves to the resource files/shared/admonitions/domestic/danger. The algorithm them loads that file and inserts the contents into the output.
match insert with key
$resource = find key in lookup-table
output $resource
To output your content for the foreign market, you simply prepare a new key lookup table:
keys:
key:
name: warn_danger
resource: files/shared/admonitions/foreign/danger
You then tell the synthesis algorithm to use this lookup table instead.
Using keys is not necessarily better than using IDs. You need some kind of bridge between the citation of an identifier in the source file and the location of a resource with that identifier in the content store. This bridge can be created by a key lookup table, by remapping file URLs, or by modifying a query to a content repository.
One feature of the key approach is that, because it does not attach the key directly to the content, it can be used to identify resources that do not have IDs, which may include resources that you do not control.
We should note that any ID can be treated as a key simply by locating it in a lookup file. In fact, that is all a key really is: an ID that is located in a lookup file instead of directly in a resource. As such, it is perfectly possible to create a system where some IDs are located directly in the content and some are located in lookup tables. All that is required for this to work is for the synthesis algorithm to recognize when an ID is located in a lookup table and load the resource it points to. Nonetheless, systems that support keys tend to implement them as separate structures from IDs.
One downside of a strictly external approach to keys is that they can only point to a whole resource. This could force you to keep all your reusable units in separate files. To avoid this, you can combine keys with IDs. The following example combines the foreign and domestic danger warnings into one file and gives each an ID:
warnings:
warning:(#warn_danger_domestic)
title: Danger
Be very very careful. This could kill you.
warning:(#warn_danger_foreign)
title: Look out!
Pay close attention. You could really hurt yourself.
Now we can rewrite our key lookup tables to use the IDs to pull the right warning out of this common file. For the domestic build we would use a key lookup table like this:
keys:
key:
name: warn_danger
resource: files/shared/warnings#warn_danger_domestic
And for the foreign build, one that looks like this:
keys:
key:
name: warn_danger
resource: files/shared/warnings#warn_danger_foreign
Common with conditions
In some cases of variable into common, the variant pieces will not actually be factored out into a separate file. Rather, each of the possible alternatives is included in the file conditionally.
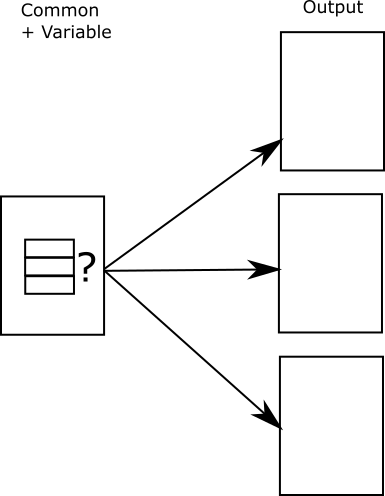 For instance in content for a car manual you might have conditional text for the number of people the car seats.
For instance in content for a car manual you might have conditional text for the number of people the car seats.
The vehicle seats {four}(?compact){five}(?midsize){seven}(?van).
Here the main text is the fixed piece and the variable pieces are the words “four”, “five”, and “seven”. Which of these will be included in the output depends on which condition is applied during the build. If the condition midsize is applied, then the output text will be “five” and the other alternatives will be suppressed.
match phrase with condition
if condition in $build_conditions
continue
else
ignore
The upside of the conditional approach is that it keeps all the variants in one file, so your algorithm does not have to know where to go to find the external content.
But there are a number of downsides to this approach:
- It gets very cumbersome to read the source if there are many different conditions applied.
- When the subject matter changes, you have to find all the places the conditions occur and update them.
- If the same data point (the number of seats) is mentioned in many different documents, that information is still being duplicated all over the content, which makes it hard to maintain and verify, and hard to change if the compact seats five in the next model year.
Common with conditions is not limited to cases where there are alternate values, however. In some cases, content may simply be inserted or omitted for certain outputs.
The main features of the car are:
ol:
li: Wheels
li: Steering wheel
li:(?deluxe) Leather seats
li: Mud flaps
In this case, the list item “Leather seats” would only be published if the condition deluxe was specified in the build. It would be omitted for all other builds. Such cases make it hard to get away from the use of conditionals as a reuse mechanism. This approach to reuse is often called “filtering” or “profiling.” Some systems have elaborate ways of specifying filtering or profiling of the content. The net effect is the same as the simple condition tokens shown here, but they may allow for more sophisticated or elaborate conditions.
Because common with conditions is essentially a form of variable into common where the variable content is contained inside the common source, it can technically be replaced by a variable into common approach in all cases. In practice, the use of conditions tends to occur when:
- The number of variations is small and thought to be fixed or to change infrequently.
- The variable pieces are eccentric or contextually dependent.
- The writer or organization wishes to avoid managing multiple files.
- The current tools don’t support variable into common.
The success of a common with conditions approach depends on what you choose for your conditional expressions. Generally, subject domain conditions will be much more stable and manageable than document domain conditions. For instance, conditions that relate to different vehicles (subject domain) are based in the real world and are therefore objectively true as long as the subject matter remains the same. Conditions that relate to different publications or different media, on the other hand, are not objectively true and can’t be verified independently. They only way to verify them is to build the different documents or media and see if you got the content you expected. This makes maintaining such conditions cumbersome and error-prone.
Factor out the common
In the article on the management domain, we noted that the subject domain alternative to using an insertion instruction for the warning text was to specify which procedures were dangerous, thus factoring out the constraint that the warning must appear. In effect, this factors out the common content as well.
procedure: Blow stuff up
is-it-dangerous: yes
step: Plant dynamite.
step: Insert detonator.
step: Run away.
step: Press the big red button.
In this case, the author does not have to identify the material to be included, either directly by file name or indirectly through an ID or a key. Instead, it is up to the algorithm to include it:
match procedure/is-it-dangerous
if is-it-dangerous = 'yes'
output files/shared/warnings#warn_danger_domestic
To produce the foreign market version of the documentation, you simply edit the rule:
match procedure/is-it-dangerous
if is-it-dangerous = 'yes'
output files/shared/warnings#warn_danger_foreign
The beauty of this approach is that the content is entirely neutral as to what kind of reuse may be going on or how dangerous procedures may be treated. Because the content itself contains only objective information about the procedure itself, you can implement any algorithm you like to publish or reuse the content in any way you like, at any time, based on this information. By making the content not specific to any form of reuse or any reuse mechanism, we effectively make it much more reusable.
At the same time, we also make the content much easier to write, since this approach does not require the writer to know how the reuse mechanism works, how to identify reusable content, or even that reuse is occurring at all. All they have to do is answer a simple question about the content — one to which they should already know the answer.
Structured writing is about factoring invariants and complexities out of content, and this approach enables the widest range of reuse possibilities while factoring all the complexities of reuse out of the content.
Factor out the variable
You can also factor out the variable content. For example, in the case of the different models of a car, rather than conditionalizing the list of features in the document, like this:
The main features of the car are:
ol:
li: Wheels
li: Steering wheel
li:(?deluxe) Leather seats
li: Mud flaps
You can factor out the list entirely:
The main features of the car are: >>>(%main_features)
You can then maintain the features list in a database. The organization probably already has a database of features for each vehicle, so we don’t need to create anything new. We simply query the existing database. (After all, this is about reusing what already exists rather then recreating it!)
So now our algorithm looks something like this:
match insert with key
$resource = lookup key in lookup-table
output $resource
We then have a key lookup table where the resource is identified by a query on the database
keys:
key:
name: %warn_danger
resource: from vehicles select features where model = $model
This retrieves a different set of features from the database depending on how the variable $model is defined for the build. Launch the build with $model = ‘compact’ and you get the feature set for the compact model. Launch the build with $model = ‘van’ and you get the feature set for the van model.
Naturally, this is leaving out a whole lot of detail about how this query gets executed and how the results get structured into a document domain list structure. But these are implementation details that vary greatly .
Assemble from pieces
In the assemble from pieces approach, there is no common vs. variable distinction and no single source document into which reused content is inserted or to which conditions are applied. Instead, there is a set of content units that are assembled to form a finished document.
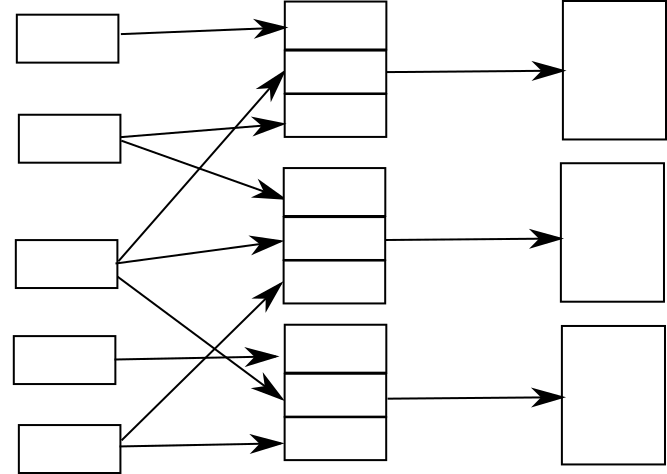 For example, if you have a range of products with common features, you might assemble the documentation for those products using a common introduction with a piece representing each feature of each model.
For example, if you have a range of products with common features, you might assemble the documentation for those products using a common introduction with a piece representing each feature of each model.
This could be a flat list, or it could be a tree structure. For instance, you might assemble a chapter of a manual with a introductory piece and then several sections below it in the tree.
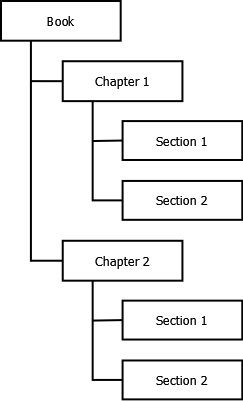 The assembly approach requires a structure to describe how the units are assembled. This structure is often called a map. (It is called a map in DITA, for instance.) Some applications may also refer to it as a table of contents.
The assembly approach requires a structure to describe how the units are assembled. This structure is often called a map. (It is called a map in DITA, for instance.) Some applications may also refer to it as a table of contents.
map: Widget Wrangler Deluxe User Manual
unit: units/ww/deluxe/intro
unit: units/ww/shared/basic_features
unit: units/ww/deluxe/deluxe_features
unit: units/ww/shared/install/intro
unit: units/ww/shared/requirements
unit: units/ww/deluxe/requirements
unit: units/ww/shared/install
unit: units/ww/deluxe/install_options
Note that a map does not always have to be written by hand by an author. In some cases the map may be created by an algorithm based on the metadata of the units themselves. Whether this is possible depends on what determines the desired order of units. If the assembled units are supposed to form a narrative flow, they may need to be ordered by hand, as it is difficult to generate a narrative ordering from metadata. But if the units do not form a narrative flow, they can easily be ordered using metadata. For instance, if you are assembling a cookbook from recipe units you might order them by season or main ingredient without caring if the boiled egg recipe comes before or after the scrambled egg recipe.
Rather than using a map, you can allow the units themselves to pull in other units, which may in turn pull in other units. So the Widget Wrangler Deluxe install introduction unit might look like this:
unit: Installing the Widget Wrangler Deluxe
You should be very careful when installing the Widget Wrangler Deluxe. Follow these steps carefully:
>>>(unit units/ww/shared/requirements)
>>>(unit units/ww/deluxe/requirements)
>>>(unit units/ww/shared/install)
>>>(unit units/ww/deluxe/install_options)
This avoids the need for a map, but the downside is that it can make the units less reusable. In the above example, for instance, you would need a separate introduction unit for the regular Widget Wrangler since the introduction file imports all the requirements and procedural units. By assembling units with the map, you can use a shared install intro, which increases the amount of reuse you can do.
When using the map approach, you must think about how your content will single source to paper-like media and hypertext media. Some people will output the same map to to both media. In hypertext media that usually results in the map being turned into a table of contents, often displayed in a separate pane as in a help system. This may be fine if you are creating a help system, but it is not how Web content is usually displayed. Others will single source content that uses the assemble-from-pieces approach to create completely separate maps — or even to use completely different assembly techniques that don’t involve maps at all — to produce paper-like and hypertext outputs. This can help you to work around some of the design limitations that we talked about in the single sourcing article.
Of course, there is one problem with the idea of using a common install intro for both the regular and deluxe widget wrangler. The intro mentions the name of the product. To solve this problem without requiring two different units, we can use the variable into common or common with conditions reuse techniques within the intro unit. Here is an example using variable into common:
unit: Installing the >($product_name)
You should be very careful when installing the >($product_name). Follow these steps carefully:
>>>(unit unit/ww/shared/requirements)
>>>(unit unit/ww/deluxe/requirements)
>>>(unit unit/ww/shared/install)
>>>(unit unit/ww/deluxe/install_options)
There are a number of ways in which you can mix and match the basic reuse patterns to achieve an overall reuse strategies. Most systems designed to support reuse will allow you to do all these patterns and to combine them however you wish.
Content reuse is not a panacea
Content reuse can seem like an easy win, and in some cases it can return substantial benefits, but there are pitfalls to be aware of. You will need to plan carefully to make sure that you avoid the traps that await the unwary.
Quality traps
There are three main quality traps with content reuse.
- Making content too generic
- Losing the narrative flow
- Failure to address the audience appropriately
Many works on content reuse casually recommend making content more generic or more abstract as a means to making it more reusable, without mentioning the potential downside. This is very dangerous and can do serious harm to the quality of your content. Statements that are specific and concrete are easier to understand and communicate better than statements that are generic and abstract. Replacing specific and concrete statements with generic or abstract statements will reduce the effectiveness of your content significantly.
Unfortunately, human beings suffer from the curse of knowledge. The curse of knowledge is a cognitive bias that makes it very hard for people who understand an idea to appreciate the difficulties that idea presents to people who do not understand it. The curse of knowledge makes the generic or abstract statement of an idea appear equally communicative, and perhaps more succinct and precise, than the concrete and specific statement of it. Writers are subject to the curse of knowledge at all times, which pulls them away from the kind of specific and concrete statement that make ideas easier to comprehend. The desire to make content reusable reinforces this temptation.
Replacing the specific and concrete with the generic and abstract always reduces content quality and effectiveness. You may decide that the economic benefits of content reuse outweigh the economic costs of less effective content, but you should at least be aware that there are real economic consequences to this choice.
Another potential quality problem comes with the loss of narrative flow. Not all content has or needs a lengthy narrative flow, but if you start breaking your content into reusable units and putting them back together in different ways, the narrative flow can easily be lost. In some cases you can avoid this problem by making the topics you present to your audience more self contained using an Every Page is Page One information design. But don’t assume that you have an effective Every Page is Page One design just because you have broken your content into reusable units. If that content was written in a way that assumed a narrative flow, it is not going to work when reused in a way that breaks that flow.
Finally, reuse can encourage us to come up with one way of telling our story that we present to all audiences. But not all audiences are alike, and the way we tell our story to one audience may not work for another audience. Good content tells a good story to a particular audience. Two different tellings of the same story do not constitute redundant content if they address different audiences.
Cost traps
It is easy to see content reuse as a big cost saving. Reusing content means you do not have to write the same content over and over again. It is easy to add up the cost of all that redundant writing and regard that number as pure cost savings from a content reuse strategy.
But all of the reuse techniques create multiple artifacts that need to be managed. This includes both content and processing code. You need a mechanism to make sure that your content obeys the constraints required to make the pieces of content fit together reliably, and that the way you have done reuse actually produces the documents you want. The cost of such management can be non-trivial and the consequences of the management breaking down can be significant.
Where costs can really mount, though, it when it comes to modifying the content when the subject matter changes. Often, you cannot find out if the content you treated as common is really common until the subject matter changes. If it turns out not to be common, you may have a complex management task to sort out what is really common and what isn’t. This can involve complex edits that then have to be tested and verified. If you get everything right, you can realize major savings when it comes time to modify your content, but if you get it wrong, it can multiply costs.
If you do not audit and validate your content collection and its web of reuse relationships regularly, it can become chaotic over time and lose cohesion. As a result, adding new content or changing existing content becomes increasingly difficult and expensive.
Some content reuse techniques are easy to use in non-structured ways, and early in a project it may seem like a non-structured approach to reuse speeds things up by allowing writers to reuse content wherever they find it. Over time, however, this approach can lead to a rats’ nest of dependencies and relationships between bits of content that makes it hard to update or edit the content with any confidence. If you take a disciplined approach to reuse from the beginning, you avoid problems down the road.
Depending of the techniques you use, content reuse strategies can complicate the lives of authors, which may reduce the pool of authors you can use or reduce their productivity. As the size of the content set grows, it can take longer and longer to determine if reusable content exists and to find and reuse it. It is possible for this to end up costing more time than was saved by not rewriting content. (Reuse techniques that factor out the reuse from the author’s work avoid this problem.)
Once the cohesion and discipline of a content set starts to break down, the decline tends to accelerate. As it becomes harder to find content to reuse, more duplication occurs, which further complicates the search for reusable content, creating a vicious circle. As links and other content relationships break down, people tend to form ad hoc links and relationships to get a job finished, further tangling the existing rats’ nest. Under the gun, it is almost always easier to get the next document out by ignoring the structure and discipline of the content set structure, but the effects of this are corrosive. Without consistent discipline, even in the face of deadlines, a reuse system can fail over time.
All of these issues can be managed successfully with the right techniques and the right tools, but they all introduce costs as well, both up-front costs and ongoing costs. You must reckon up those costs and subtract them from the projected cost savings before you can determine if a content reuse strategy is really going to save you money.