 All structured writing must eventually be published. Publishing structured content mean transforming it from the domain in which it was created (subject domain, document domain, or the abstract end of the media domain) to the most concrete end of the media domain spectrum: dots on paper or screen.
All structured writing must eventually be published. Publishing structured content mean transforming it from the domain in which it was created (subject domain, document domain, or the abstract end of the media domain) to the most concrete end of the media domain spectrum: dots on paper or screen.
In almost all structured writing tools, this process is done in multiple steps. Using multiple steps makes it easier to write and maintain code and to reuse code for multiple purposes.
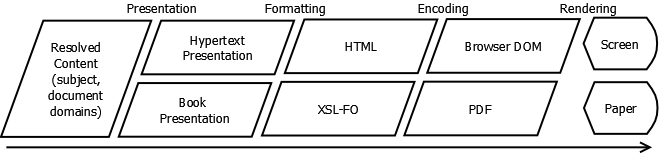
In this article, I describe the publishing process as consisting of four basic algorithms which I have mentioned in passing in earlier articles: the synthesis, presentation, formatting, and encoding algorithms. This is a model of the publishing process. All the processes in the model have to occur somewhere in every actual publishing process, but the organization of those processes may be subdivided or sequenced differently from this model. I formalized these four stages in the SPFE architecture (which I will discuss later), but I think they are a fair representation of what goes on in most publishing tool chains. To understand the requirements of each stage and the impact on the structured writing, we’ll look at the process from finished output backwards to creation and synthesis.
The Rendering Algorithm
There is actually a fifth algorithm in the publishing chain, which we can call the rendering algorithm. The rendering algorithm is the one responsible for actually placing the right dots on the right surface, be that paper, screen, or a printing plate. But this is a low-level device-specific algorithm and no one in the structured writing business is likely to be involved in writing rendering algorithms. The closest we ever get is the next step up, the encoding algorithm. However an introduction to rendering is important to understanding the four publishing algorithms work together.
 The rendering algorithm requires some form of input to tell it where to place the dots. In writing, this usually comes in the form of something called a page description language. Like it sounds, this is a language for describing what goes where on a page, but in higher level terms than describing where each dot of ink or pixel of light is placed. A page description language deals in things like lines, circles, gradients, margins, and fonts.
The rendering algorithm requires some form of input to tell it where to place the dots. In writing, this usually comes in the form of something called a page description language. Like it sounds, this is a language for describing what goes where on a page, but in higher level terms than describing where each dot of ink or pixel of light is placed. A page description language deals in things like lines, circles, gradients, margins, and fonts.
One example of a page description language is PostScript. We looked at a small example of PostScript in the article on the media domain:
100 100 50 0 360 arc closepathstroke
The Encoding Algorithm
Since most writers are not going to write directly in a page description language, the page descriptions for your publication are almost certainly going to be created by an algorithm. I call this the encoding algorithm.
While it is possible that someone responsible for a highly specialized publishing tool chain may end up writing a specialized encoding algorithm, most encoding algorithms are implemented by existing tools that translate formatting languages into page descriptions languages.
 There are several formatting languages that are used in content processing. They are often called typesetting languages as well. XSL-FO (XSL – Formatting Objects) is one of the more commonly used in structured writing projects. TeX is another.
There are several formatting languages that are used in content processing. They are often called typesetting languages as well. XSL-FO (XSL – Formatting Objects) is one of the more commonly used in structured writing projects. TeX is another.
Here is an example of XSL-FO that we looked at in the article on the single-sourcing algorithm:
<fo:block space-after="4pt"><fo:wrapper font-size="14pt" font-weight="bold">Hard Boiled Eggs</fo:wrapper></fo:block>
You process XSL-FO using an XSL-FO processor such as Apache FOP. Thus the XSL-FO processor runs the encoding algorithm, producing a page description language such as PostScript or PDF as an output.
Writers are not likely to write in XSL-FO directly, though it is not entirely impossible to do so. In fact some boilerplate content, such as front matter for a book, does sometimes get written and recorded directly in XSL-FO. (I did this myself on one project.) So, as you construct a publishing tool chain, you will need to select and integrate the appropriate encoding tools as part of your process.
The encoding algorithm takes a high level description of a page or a set of pages, their content and their formatting, and turns it into a page description language that lays out each page precisely. For publication on paper, or any other fixed-sized media, this involves a process called pagination: figuring out exactly what goes on each page, where each line breaks, and when lines should be bumped to the next page.
The pagination function figures out, for example, how to honor the keep-with-next formatting in an application like Word or FrameMaker. It must also figure out how to deal with complex figure such as tables: how to wrap text in each column, how to break a table across pages, and how to repeat the header rows when a table breaks to a new page. Finally, it has to figure out how to number each page and then fill in the right numbers for any references that include a particular page number.
This is all complex and exacting stuff and, depending on your requirements, you may have to pay some attention to make sure that you are using a formatting language that is capable of doing all this the way you want it done.
Also, you should think about just how automatic you want all of this to be. In a high-volume publication environment, you want it to be fully automatic, but this could require some compromises. For example, writers and editors sometimes make slight edits to the actual text of a document in order to make pagination work better. This is very easy to do when you are working in the media domain in an application like Word or FrameMaker. If you end up with the last two words of a chapter at the top of a page all by itself, for instance, it is usually possible to find a way to edit the final paragraph to reduce the word count just enough to pull the end of the chapter back to the preceding page. But this sort of thing is much harder when you are writing in the document domain or the subject domain, particularly if you are single sourcing content to more than one publication or reusing content in many places. An edit that fixes one pagination problem could cause another, and a major reason for writing in those domains it to take formatting concerns off the author’s plate.
For Web browsers and similar dynamic media viewers, such as E-Book readers or help systems, the whole pagination process takes place dynamically when the content is loaded into the view port, and it can be redone on the fly if the reader resizes their browser or rotates their tablet. This means the publisher has very little opportunity to tweak the pagination process. They can guide it by providing rules such as keep-together instructions through tools like cascading style sheets (CSS), but they obviously cannot hand tweak the text to make it fit better each time the view port is resized.
The formatting language for these kinds of media is typically HTML+CSS.
The Formatting Algorithm
The formatting algorithm generates the formatting language that drives the encoding and pagination process. In other words, the formatting algorithm produces the media domain representation of the content from content in the document domain.
 In the case of HTML output, the formatting algorithm generates HTML (with connections to the relevant CSS, JavaScript, and other formatting resources). This is the end of the publishing process for the Web, since the browser performs the encoding and rendering algorithms internally.
In the case of HTML output, the formatting algorithm generates HTML (with connections to the relevant CSS, JavaScript, and other formatting resources). This is the end of the publishing process for the Web, since the browser performs the encoding and rendering algorithms internally.
In the case of paper output, the formatting algorithm generates a formatting language, such as TeX or XSL-FO, which is then fed to the encoding algorithm as implemented by a TeX or XSL-FO processor. In some cases, organizations use word processing or desktop publishing applications to tweak the formatting of the output by having the formatting algorithm generate the input format of those applications (typically RTF for Word and MIF for FrameMaker). This allows them to exercise manual control over pagination, but with an obvious loss in process efficiency. In particular, any tweaks made in these applications are not routed back to the source content, so they must be done again by hand the next time the content is published.
The Presentation Algorithm
The job of the presentation algorithm is to determine exactly how the content is going to be organized as a document. The presentation algorithm produces a pure document domain version of the content.
 The organization of content involves several things:
The organization of content involves several things:
Ordering: At some level, content forms a simple sequence in which one piece of information follows another. Authors writing in the document domain typically order content as they write, but if they are writing in the subject domain, they can choose how they order subject domain information in the document domain.
Grouping: At a higher level, content is often organized into groups, which could be groups on a page or groups of pages. Grouping includes breaking content into sections or inserting subheads, inserting tables and graphics, and inserting information as labeled fields. Authors writing in the document domain typically create these groupings as they write, but if they are writing in the subject domain, you may have choices about how you have the presentation algorithm group subject domain information in the document domain.
Blocking: On a page, groups may be organized sequentially or laid out in some form of block pattern. Exactly how blocks are to be laid out on the displayed page is a media domain question, and something that may even be done dynamically. In order to enable the media domain to do this, the document domain must clearly delineate the types of blocks in a document in a way that the formatting algorithm can interpret and act on reliably.
Labeling: Any grouping of content requires labels to identify the groups. This includes things like titles and labels on data fields. Again, these are typically created by authors in the document domain, but are almost always factored out when authors write in the subject domain (most labels indicate the place of content in the subject domain, so inserting them is a necessary part of reversing the factoring out of labels that occurs when you move to the subject domain).
Relating: Ordering, grouping, blocking, and labeling cover organization on a two dimensional page or screen. But content also can be organized in other dimensions by creating non-linear relationships between pieces of content, including hypertext links and cross references.
Differential presentation algorithms
The organization of content is an area where the document domain cannot ignore the differences between different media. Although the fact that a relationship exists is a pure document domain issue, how that relationship is expressed, and even whether it is expressed or not, is affected by the media and its capabilities. Following links in online media is very cheap. Following references to other works in the paper world is expensive, so document design for paper tends to favor linear relationships, while document design for the web favors hypertext relationships. As a result, you should expect to implement differential single sourcing and use different presentation algorithms for different media.
Presentation sub-algorithms
The presentation algorithm may be broken down into several useful sub-algorithms, each dealing with a different aspect of the presentation process. How you subdivide your publishing algorithm depends on your particular business needs, but it may benefit you to treat these operations as separate algorithms.
The linking algorithm
How content is linked or cross-referenced is a key part of how it is organized in different media, and a key part of differential single sourcing. We will look at the linking algorithm in detail in a future article.
The navigation algorithm
Part of the presentation of a document or document set is creating the table of contents, index, and other navigation aids. Creating these is part of the presentation process. Because these algorithms create new resources by extracting information from the rest of the content, it is often easier to run these algorithms in serial after running the main presentation algorithm. This also makes it easier to change the way a TOC or index is generated without affecting other algorithms.
The public metadata algorithm
Many formats today contain embedded metadata designed for use by downstream processes to find or manage published content. One of the most prominent is HTML microformats which identify content to other services on the web, including search engines. This is a case of subject domain information being included in the output. Just as subject domain metadata allows algorithms to process content in intelligent ways as part of the publishing process, subject domain metadata embedded in the published content allows downstream algorithms (such as search engines) to use the published content in more intelligent ways.
If authors write content in document domain structures, they generally create public metadata as annotations on those document domain structures. But if they create content in the subject domain, the public metadata is usually based on the existing subject domain structures. In this case, the public metadata algorithm may translate subject domain structures in the source to document domain structures with subject domain annotations in the output.
This does not necessarily mean that the public metadata you produce is a direct copy of subject domain metadata you use internally. Internally, subject domain structures and metadata are generally based on your internal terminology and structures that meet your internal needs. Public terminology and categories (being more generic and less precise than the private) may differ from the ones that are optimal for your internal use. But because this is subject domain metadata (and thus rooted in the real world), there should be a semantic equivalence between your private and public metadata. The public metadata algorithm, therefore, not only inserts the metadata but sometimes translates it to the appropriate public categories and terminology.
The document structure normalization algorithm
In many cases, content written in the subject domain also includes many document domain structures. If those document domain structures match the structures in the document domain formats you are creating, the presentation algorithm merely needs to copy them to the document domain. In some cases, however, the document domain structures in the input content do not match those required in the output, in which case you must translate them to the desired output structures.
The Synthesis Algorithm
The synthesis algorithm determines exactly what content will be part of a content set. It passes a complete set of content on to the presentation algorithm to be turned into one or more document presentations.
The synthesis algorithm transforms content and data into a fully realized set of subject domain content. Sources for the synthesis algorithm include content written in the subject domain, document domain, or subject domain content with embedded management domain structures, and externally available subject data which you are using to generate content.
Content that contains management domain metadata, generally used for some form of single sourcing or reuse, does not represent a final set of content until the management domain structures have been resolved. In the case of document domain content, processing the management domain structures yields a document domain structure which may then be a pass-through for the presentation algorithm. In the case of the subject domain content, processing management domain structures yields a definitive set of subject domain structures which can be passed to the presentation algorithm for processing to the document domain.

Differential synthesis
We noted above that you can use differential presentation to do differential single sourcing where two publications contain the same content but organized differently. If you want two publications in different media to have differences in their content, you can do this by doing differential synthesis and including different content in each publication.

Synthesis sub-algorithms
The synthesis algorithm can involve a number of sub-algorithms, depending on the kind of content you have and its original source.
The inclusion algorithm
If your content contains management domain include instructions, such as we identified in discussing the reuse algorithm, these must be resolved and the indicated content found and included in the synthesis.
As we noted, you can also include content based on subject domain structures, without any management domain include instructions. Such inclusions are purely algorithmic — meaning that the author does not specify them in any way. It is the algorithm itself that determines if and when content will be included and where it will be included from. The inclusion algorithm also performs this task.
The filtering algorithm
If your content contains management domain conditional structures (filtering) they must be resolved as part of the synthesis process. In most cases, you will be using the same set of management domain structures across your content set, so maintaining your filtering algorithm separately makes it easier to manage.
Again, note that you may be filtering on subject domain structures as well (or instead of) on explicit management domain filtering instructions. Such filtering is, again, purely algorithmic, meaning that the author has no input into it. The filtering algorithm is then wholly responsible for what gets filtered in and out and why.
Coordinating inclusion and filtering
It is important to determine the order in which inclusion and filtering are performed. The options are to filter first, to include first, or to include and filter iteratively.
Generally, you want the filtering algorithm to run before other algorithms in the synthesis process so that other algorithms do not waste their time processing content that is going to be filtered out. On the other hand, if you run the filtering algorithm before you run the include algorithm, any necessary filtering on the included content will not get executed.
Doing inclusion before you filter addresses this problem, but creates a new one. If you include before you filter, you may include content based on instructions or subject domain structures that are going to be filtered out. This could then leave you with a set of included content that was not supposed to be there, but no easy way to identify that it does not belong.
The preferred option, therefore, is to run the two algorithms iteratively. Filter your initial source content. When you filter in an include instruction, immediately execute the include and run the filtering algorithm on the included content, processing any further filtering instructions as they are filtered in.
The rules based approach to content processing previously described in this series makes this kind of iterative processing relatively easy. You simply include both the filtering and inclusion rules in one program file and make sure that you submit any included content for processing by the same rules the moment it is encountered.
match includeprocess content at hrefcontinue
The extraction algorithm
In some cases you may wish to extract information from external sources to create content. This can include data created for other purposes, such as application code, or data created and maintained as a canonical source of information, such as a database of features for different models of a car. We will look at the extraction and merge algorithms in a later article.
The cataloging algorithm
The synthesis algorithm will produce a collection of content, potentially from multiple sources. This collection is then the input to the presentation algorithm. For the presentation algorithm to do its job, it needs to know all of the content it has to work with. In particular, the TOC and index algorithms and the linking algorithm need to know where all the content is, what it is called, and what it is about. They can get this information by reading the entire content set, but this can be slow, and perhaps confusing if the structure is not uniform. As an alternative, you can generate a catalog of all the content that the synthesis algorithm has generated which can then be use by these and other sub-algorithms of the presentation algorithm to perform operations and queries across the content set.
The resolve algorithm
When we create authoring formats for content creation, we should do so with the principal goal in mind of making it as easy as possible for authors to create the content we require of them. This means communicating with them in terms they understand. This may include various forms of expression that need to be clarified based on context before they can be synthesized with the rest of the content. This is the job of the resolve algorithm. Its output is essentially a set of content in which all names and identifications are in fully explicit form suitable for processing by the rest of the processing chain.
Content written in the subject domain is not always written in a fully realized form. When we create subject domain structures, we put as much emphasis as we can on ease of authoring and correctness of data collection. Both these aims are served by using labels and values that make intuitive sense to authors in their own domain. For example, a programmer writing about an API may mention and markup a method in that API using a simple annotation like this:
To write a Hello World program, use the {hello}(method) method.
In your wider documentation set, there may be many APIs. To relate this content correctly in the larger scope you will need to know which API it belongs to. In other words, you need this markup:
To write a Hello World program, use the {hello}(method (GreetingsAPI)) method.
The information in the nested parentheses is a namespace. A namespace specifies the scope in which a name is unique. In this case, the method name hello might occur in more than one API. The namespace specifies that this case of the name refers to the instance in the GreetingsAPI.
Rather than forcing the programmer to add this additional namespace information when they write, we can have the synthesis algorithm add it based on what it knows about the source of the content. This simplifies the author’s task, which means they are more likely to provide the markup we want. (It is also another example of factoring out invariants, since we know that all method names in this particular piece of content will belong to the same API.)
Combining algorithms
As we have seen, structured writing algorithms are usually implemented as set of rules that operate on structures as they encounter them in the flow of the content. Since each algorithms is implemented as a set of rules, it is possible to run two algorithms in parallel by adding the two sets of rules together to create a single combined set of rules that implements both algorithms at once.
Obviously, you must take care to avoid clashes between the two sets of rules. If two set of rules act on the same structure, you have to do something to get the two rules that address that structure to work together. (Different tools may provide different ways of doing this.)
Sometimes, though, one algorithm needs to work with the output of a previous algorithm, in which case, you need to run them in serial.
In most cases, the major algorithms (synthesis, presentation, formatting, encoding, and rendering) need to be run in serial, since they transform an entire content set from one domain to another (or from one part of a domain to another). In many, but not all, cases the sub-algorithms of these major algorithms can be run in parallel by combining their rule sets since they operate on different content structures.
The consistency challenge
The biggest issue for every algorithm in the publishing chain is consistency. Each step in the publishing chain transforms content from one part of the content spectrum to another, generally in the direction of the media domain.
The more consistent the input content is, the easier it is for the next algorithm in the chain to apply a simple and reliable process to produce consistent output, which in turn simplifies the next algorithm in the chain, making it more reliable.
Building in consistency at source is therefore highly desirable for the entire publishing algorithm. This presents an interesting problem, because good content by its nature tends to be diverse, and therefore less consistent and more prone to exceptions. It is the stuff that does not fit easily into rows and columns.
One approach to this problem is to write all the content in a single document domain language such as DocBook. Since all the content is written in a single language it is theoretically completely consistent and therefore should be easy to process for the rest of the tool chain.
The problem with this is that any document domain language that is going to be useful for all the many kinds of documents and document designs that many different organizations may need is going to contain a lot of different structures, some of which will be very complex and most of which will have lots of optional parts. This means that there can be thousands of different permutations of DocBook structures. A single formatting algorithm that tried to cover all the possible permutations could be very large and complex—and likely very hard to maintain.
The alternative is to have authors write in small, simple subject domain structures that are specific to your business and your subject matter. You would then transform these to a document domain language using the presentation algorithm. This document domain language could still be DocBook, but now that you control the DocBook structures that are being created by the presentation algorithms, you don’t have to deal with all the complexities and permutations that authors might create in DocBook, just the structures that you know your presentation algorithm creates.
These subject domain documents would have few structures and few options and therefore few permutations. As a result, the presentation algorithms for each could be simple, robust, and reliable, as well as easy to write and to maintain. You could also do differential single sourcing by writing different presentation algorithms for each media or audience.
The trade-off, of course, is that you have to create and maintain the various subject domain formats you would need and the presentation algorithms that go with them. It’s a trade-off between several simple structures and algorithms and a few complex ones.