From the Edi
tor: Summer gives us an opportunity to revisit some of our popular posts, and you can check into something you might have missed. Today’s replay, from Jacquie Samuels first appeared on February 11, 2014. As more and more organizations consider DITA implementations, it’s worth a look at the underlying rationale to see what your organization has in common, and can learn from, these pain points.
 The people in your organization who control the budgets look hard at things like ROI, productivity, KPI (Key Performance Indicators), and resolving business pain points before agreeing to open the company wallet. Among the items you need to make the case for implementing DITA (Darwin Information Typing Architecture) is solid proof of the pain points it can solve. And face it, documentation of any kind, coming from any source in your organization, suffers from some common pain points –ones that DITA solves beautifully.
The people in your organization who control the budgets look hard at things like ROI, productivity, KPI (Key Performance Indicators), and resolving business pain points before agreeing to open the company wallet. Among the items you need to make the case for implementing DITA (Darwin Information Typing Architecture) is solid proof of the pain points it can solve. And face it, documentation of any kind, coming from any source in your organization, suffers from some common pain points –ones that DITA solves beautifully.
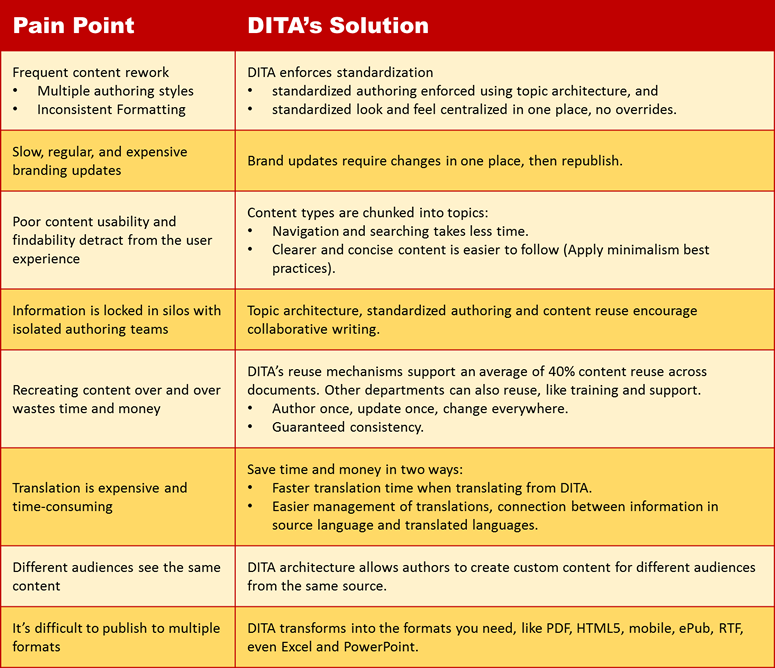
Pain Point #1: We have no standards for content and face constant rework
If you can easily identify the author of a piece of writing, then your content isn’t standardized. If you can tell the age of the information just by looking at the PDF, your content isn’t standardized. And if it’s not standardized, authors are redoing the same work.
It’s hard to keep content looking and sounding consistent, especially if you have more than one author creating content. Your authors are likely using different templates (or none at all), different tools, a different writing style, different standards, or different organizational techniques.
Your content is a direct reflection of your products and your company. If your content (and that includes any content meant to be read by someone else–from support articles to user assistance to marketing bulletins) looks disorganized, inconsistent, and unprofessional, then so does your company. Just as important, your company is losing money through inefficiencies and duplication of efforts.
DITA address the pain that comes from lack of standards. It encourages and enforces a standardized authoring style as well as standardized formatting.
Authoring Style
DITA’s use of XML means that authors must follow a specific way of writing. For example, when writing a procedure, the context of the task, which is the “why” of why a person would want to actually perform this task, must precede the actual steps. The steps themselves are separated from the results of those steps. A well-written task includes all the information that a user needs to perform that task and not a word more. It is separated from any additional discussions, feature descriptions, or related information that is not immediately pertinent for the user.
The architecture that DITA includes works like a blueprint for good, clear writing. If everyone is writing in DITA, then you achieve your consistency with very little effort and just a few style guide decisions.
DITA industry leader Keith Schengili-Roberts agrees that the quality improvements that follow from DITA implementation are invaluable to authors:
One of the things I think is talked about the least regarding the benefits of DITA is the discipline it instills in a writing team that is implementing it, raising the bar for the quality of writing that technical authors produce. The structured approach to writing means that technical authors have to put more thought into how they plan to write a topic, rather than just writing the first thing that comes into their head. It has helped move technical authoring away from the old “cottage industry” mentality of one-off production, producing content that is more focused on the reader’s needs. It also creates more incisive and thoughtful technical authors who have to plan ahead and write for content reuse for themselves in the future and for others. The structure imposed by DITA ends up making technical authors better writers.
Formatting
Font type, font size, heading usage, spacing, alignment, bullet placement and sizing, use of special characters—these are just some of the aspects of your content that can quickly get out of sync. It’s rarely feasible to keep hundreds or thousands of documents with a standard format, especially when branding requirements evolve, with changes every few years.
In DITA, because format is completely separate from content, there is no way for formatting idiosyncrasies to creep in. An easy example is the way you instruct a user to select first one selection, then something that becomes visible only after the first selection.
|
Many Possibilities in Unstructured Content File…New. File, New. File, then New. New, under File. File > New. |
|
One Possibility in DITA XML <menucascade> <uicontrol>File</uicontrol><uicontrol>New</uicontrol> </menucascade> |
Which, when published always looks the same. So if you want to use the > sign, then it always looks like File > New. But the author never, ever has to type in the > sign. They throw the appropriate tags around the words and consistency is guaranteed.
Pain Point #2: We can’t keep up with brand updates and format changes
Formats change. Fonts change, colors change, logos change, styles get updated and need a refresh. This is a massive problem for anyone not using DITA (or another XML architecture). The user guides, quick reference cards, tutorials, web-based help, knowledgebase articles, and so forth, can number in the thousands. Updating and applying FrameMaker templates and styles, or Word styles—even if everything is set up correctly and correctly—is still a huge and painful process.
Just as with Pain Point 1, where your formatting is consistent because it’s all central, DITA solves the update dilemma with ease. It makes updating your format much, much easier, because you make the changes in one spot, once. Then just re-publish your documents and they’ll have the new format.
Pain Point #3: Our customers/clients/employees can’t use the content we have
For every customer or help desk agent who complains that they can’t find the right information buried in long PDFs or confusing KB articles, there’s at least a dozen who don’t complain, but still can’t find what they need. Unsatisfactory customer experiences because of unusable content do damage to your brand and your bottom line.
DITA helps increase content usability by applying topic-based writing best practices to content. Instead of having to read long chapters of mostly irrelevant information, the end users can quickly access succinct pieces of content that have appropriately chunked information.
In addition, DITA encourages authors to put the right information in the right topic type.
Users, when accessing documentation, are mostly looking to figure how to do something—from file renaming to assembling a gadget properly. When authors create the information using the topic types of task, concept, and reference, they separate each particular type from the other types. This allows users to navigate right to the steps on how to do something without having to read the extensive background information. If they need that background information or command line syntax, then they navigate to those particular topics.
Content is no longer jumbled together. It’s separated, it’s findable, and it’s content that users appreciate.
Pain Point #4: Our teams work in Silos and know only their own subject matter
In many companies, one person or group of people will write for a particular area, product line, solution, or type of content. They end up playing their strengths and generally sticking to what they become good at. Authors might even point out that this helps streamline the content creation lifecycle for that one area because they don’t constantly have to learn the ins and outs of writing for a new area.
DITA promotes collaborative authoring, breaking down those silos to a great degree. Because all the topics, element use, tools, and publishing processes are standardized for all authors across all teams, moving to a new area requires learning about the subject matter, the new team members, and the new project dates and absolutely nothing more.
Pain Point #5: Authors waste effort writing content repeatedly
It’s the information age and we write. We write a lot. We tend to write a lot of the same stuff over and over again, for different products, different people, at different times, and more likely than not, in slightly different ways.
Some writers feel that it’s actually important to vary their words when trying to say the same thing, as though they’re authoring an essay in school.
There are two problems with this approach. We are
- being inconsistent
- wasting time
Inconsistency is a problem because you’re forcing your readers to try and decipher something twice, known in academic circles as adding to their cognitive load. You used different words or different grammar and they’re left trying to decide why things are different—because there must be a reason, right? Best practice: don’t make people work when they’re reading your content. It annoys them.
By “wasting time,” I don’t mean you’re wasting 2 minutes a day and it’s no big deal. I mean you’re wasting 2 minutes a day x 20 writers x 330 days per year. That’s 220 hours or roughly $11,000 and that’s just for one tiny little possible piece of reuse.
Here’s a perfect example of a reuse candidate: “Select OK to confirm or Cancel to return to the previous screen. If you select Cancel, your settings remain loaded and you are able to edit them further or return to the main menu.” No need to use synonyms for words like “confirm” or “remain” or even “return” when this instruction shows up for another feature.
Now, just imagine when there’s a change to the product. Suddenly, Cancel actually takes you back to the home screen immediately. If you haven’t set it up for reuse, all of a sudden, you have to edit a zillion phrases.
Reuse can be small, like this, or large, such as an entire topic or even set of topics. It can also be extra large, such as a case where you’re creating entire secondary deliverables from exactly the same content. Separate user’s guides geared for novice and advanced users? It’s absolutely possible to do this in DITA with very little extra effort from the authors.
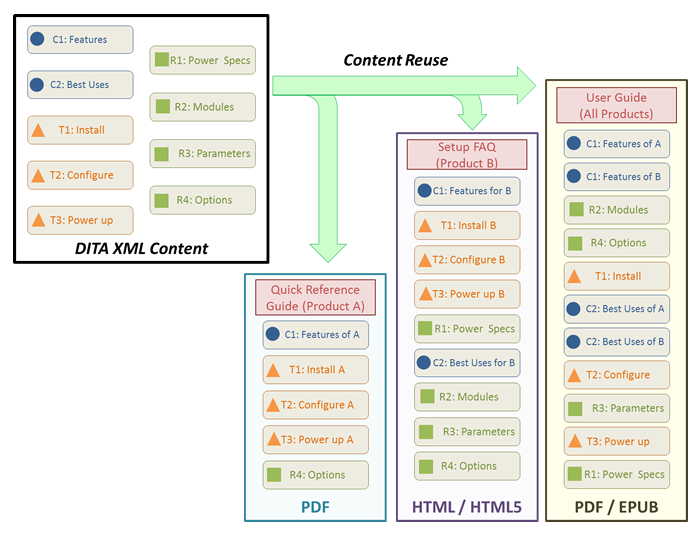
The benefits of content reuse from implementing DITA resolve pain points such as creating content over and over.
Bernard Aschwanden, Owner of Publishing Smarter, consultants in Technical Writing and Management says:
Many companies experience documentation headaches that DITA can attack. This includes content reuse—true reuse of content, not just short phrases, variables, or shared images, but rather products that share many features and a lot of policy and procedure, or any documents that contain larger shared content. With DITA, the ideals of content reuse beyond fragments of content become far more realistically applied. There is upfront time and effort, but having a solid reuse model means that there is less time spent on the peripheral support of documentation as well as the core writing. One set of source materials means one review, one approval, one pass by legal, one translation pass per language, one set of documents to maintain, and it can even mean that the “next” release of the product and documentation is dramatically faster. With that one source to work from it becomes easier to know what to do between releases. Check the one source, decide what remains the same, what needs to be removed or added, and what needs to be edited. With those decisions made the entire creation of the second set of materials becomes much, much quicker than the first version.
Time and money are saved when you use DITA correctly and implement a second release, or have large reuse of content across product lines, platforms, audiences, or other identified mixed delivery (such as multiple output types for multiple channels).
There are hundreds or even thousands of possible reuse candidates in every single set of content out there. That’s a lot of wasted time.
Dr. JoAnn Hackos, owner of ComTech and executive director of the Center for Information Development Management describes the payoff for one client implementing DITA:
Repurposing content is simple, as long as you label content elements using DITA semantics. I worked with an organization that needed to print a quick reference card for their telephone customers. All the information needed for the quick reference card, simple titles and minimal instructions, was already part of the users’ manual. Because a DITA tasks correctly labels titles and steps and allows you to select the topics you want by using filtering, the team was able to extract and appropriately style all the content for the quick reference cards in all languages. It took seconds rather than days.
Remember that by using semantic labels, you create a database of text that you can manipulate in ways you never thought possible.
In DITA, a sentence is something that is authored once, then pulled in everywhere it’s needed. It’s consistent, it’s easily managed, and when you need to update it, you update it once, in one spot, and it automatically updates everywhere it’s been used. You’ve just saved all your authors another hour or two every time the product changes, which is about a thousand times every year.
No more wasted content.
Pain Point #6: Translation costs a lot and takes too long
If you ask your translation vendor about the relative cost of translating DITA (or even better, a related standard called XLIFF that you can use with DITA), they will tell you you’ll be saving 50% of your translation costs on average.
Once content is separated from format, which is what having it in XML does, it’s easier for translation memories to store and retrieve that translated content (retrieving one phrase or sentence rather than multiple versions of the same information). Because content is tagged based on what type of content it is, it also helps translators be more accurate.
Companies can find substantial savings using DITA in the management of translations, which is a major issue for anyone with live documents. Without XML, when the source language is updated, nothing connects it with the already-translated content, so you don’t have notifications when it needs to be translated again.
Although there are some tools involved (such as a CCMS), you can automate management of translations so that when changes are made to source, you
- know when and what content needs to be re-translated, and
- can send just that topic for translation.
Multiply a single instance by the number of languages, and potential updates, and you can see that huge savings are possible for anyone translating content.
Pain Point #7: Different audiences see the same content
Companies that produce complex, interchangeable or customizable products have needs for content that may vary depending on the conditions of who will read it in what context. Often, the authoring teams resort to convoluted workflows and multiple nearly identical projects to ensure that they keep the right content in front of the right audience.
DITA architecture solves this pain point because it allows authors to create custom content for different audiences from the same source.
They use one set of topics to author for both audiences, using attributes on elements to tag when a piece of information belongs solely to one audience and not to the other.
Authors can then create variations on the document and end up with two guides, each one targeted for a specific audience.
Pain Point #8: I can’t easily publish to multiple formats
Customers want their information their own way, and publishing only PDFs of your user assistance will create major issues for people trying to get help using their smartphone.
XML transforms relatively easily into multiple formats. Some of the most common ones are PDF, HTML, HTML5, and ePub. But it’s also possible to transform DITA into Excel, RTF, and even PowerPoint.
The limits of transforming XML into other formats are primarily based on your skill, time, and imagination. However, I find that it definitely helps to work with someone very experienced with XSLT, the XML transform language, who can either teach you or do the work for you. You only need to set up the transform once for each output you need, so it’s a big up front effort with a long-term pay off.
Summary
A solid DITA implementation can solve the major content production pain points many organizations experience, while opening the door to new opportunities and process improvements that transform more than content.
May We Suggest? Resources for DITA
Elsewhere on TechWhirl
- What is DITA?
- Tech Writer Tips & Tricks—DITA
- Lightweight DITA: A Preview from Michael Priestly
- Discussion List Archives